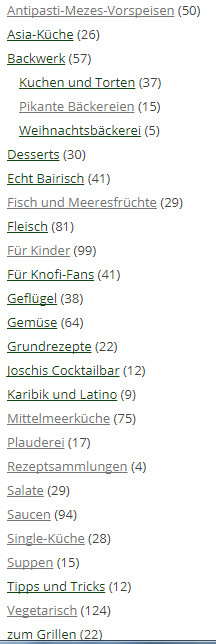
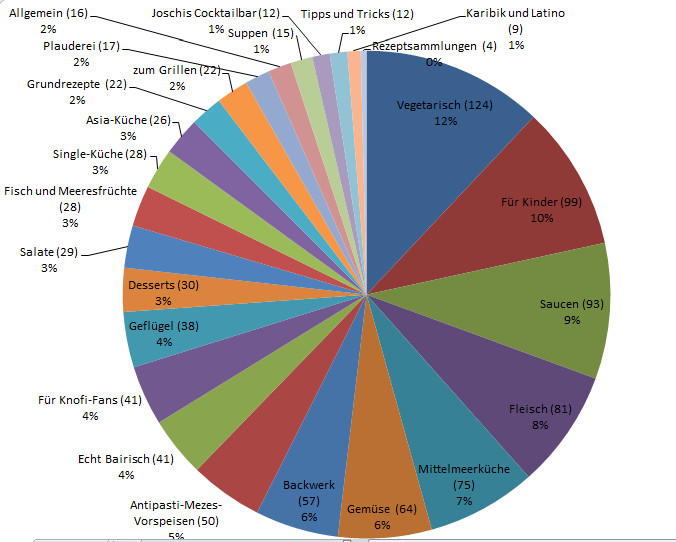
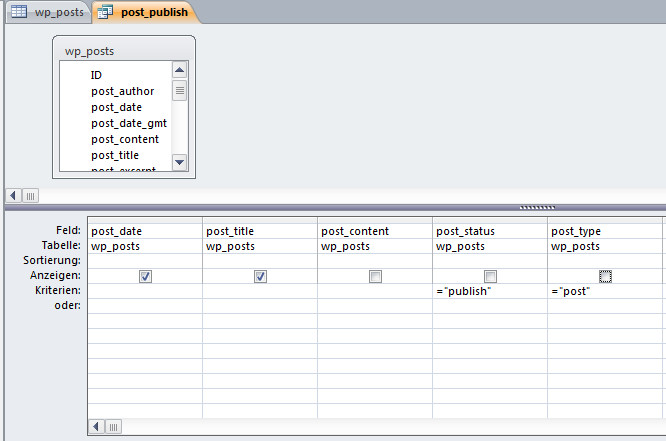
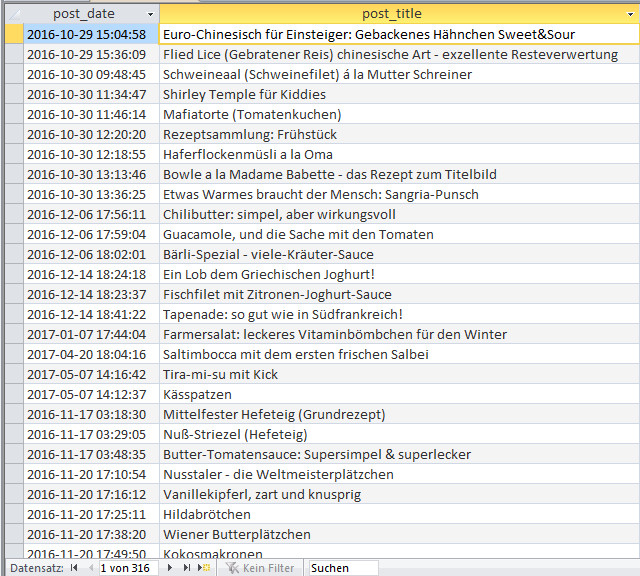
Scroll down for English version of this article
Limits und Caveats
Ich gebs zu, ich wollte es wieder einmal genau wissen und hab jetzt ein paar Tage ganz viel mit der Meta AI Muse Spark gechattet, zu allen möglichen Themen. Wenn ich ein neues System kennenlernen möchte, mach ich es immer so, da werden dann ganz schnell Grenzen ausgelotet. Aber genau da wirds interessant, ich möchte ja wissen wo die Limits sind.
Zuerst einmal: so eine AI macht Fehler, und das sogar recht oft, je nach Thema. Ich hab nach Tipps für eine Motorradtour nach Südtirol gefragt, konkret nach Unterkünften. Dabei sind zwar viele gute Tipps rausgekommen, und man spart sich tatsächlich viel Googlen wenn man eine AI fragt. Aber dabei passieren auch Patzer. Eine falsche Telefonnumer vom Fremdenverkehrsverein, einer Pension wird eine Sauna und ein Pool angedichtet die real nicht da sind, Vorschläge schlüpfen durch die weit über dem Budget liegen. Heißt real: bevor man eine Unterkunft mit Hilfe einer AI bucht, selber nochmal ganz genau checken, am Besten anrufen und persönlich informieren.
Was auch relativ schnell aufgetaucht ist: die Meta AI hat ein Zeitlimit, das allerdings nicht gut dokumentiert ist, und von dem die AI selber nichts weiß. Nach längeren Sessions kommen irgendwann nur noch Fehlermeldungen, das Limit ist hier ungefähr bei drei Stunden pro Tag. Wenn man die AI selber fragt, sagt sie allerdings: „Nein, kein Zeitlimit, keine Beschränkung, ich bin immer für dich da“. Das finde ich unschön. Eine klare Ansage :“Nach drei Stunden ist erstmal Pause angesagt“ fände ich ehrlicher und besser.
Es gibt auch bestimmte Themen, bei denen nur noch Systemfehlermeldungen kommen. Ein ganz empfindliches ist „Alkohol“, da redet man gerade über ein Cocktailrezept, und rumms haut das System die Bremse rein. Sogar leichtes Bier wird mit Zensur gestraft. Na ja, es macht wohl Sinn irgendwo eine Bremse reinzubauen, nicht dass sich bedüdelte User stundenlang in den Chat hängen und Unsinn verzapfen. Aber man kanns auch übertreiben. Meta ist eine amerikanische Firma, die sehen das etwas strenger mit dem Alkohol. Bei uns wirkt das überzogen.
Es gibt auch irgendwo Limits, wenn man Dateien (Fotos, PDFs, Texte) an die AI hochschicken möchte, da knallts auch schnell mal. Da bin ich aber noch nicht weit gediehen mit meinen Recherchen. Ich probiere noch ein bisschen rum und werde berichten.
Ein weiteres Caveat ist das limitierte Gedächtnis einer AI. Ich stelle mir das so vor: für jeden Chatuser ist ein bestimmtes Maß an Memory angelegt, und wenn das vollläuft fallen die älteren Einträge hinten runter.Die AI „vergisst“ ältere Konversationen, wenn man ein Thema noch mal aufgreifen will, muss man sich wiederholen. Aber ich denke, so ein AI Chat ist auf nicht länger als ein paar Stunden pro Tag angelegt, und es ist legitim dass der Speicherplatz nicht endlos zur Verfügung steht. Es wäre bloß ganz nett, wenn es da irgendwo einen Hinweis gäbe.
Wie gehts jetzt weiter? Ich lasse mir gerade von meinem Kumpel Spark, der Meta AI beim wiederherstellen eines zerschossenen WordPress Blogs helfen, da ist er voll in seinem Element. Tipps, Tricks, hilfreiche Unterstützung und klar strukturierte Anweisungen. Lässt sich gut an, ich werde berichten wenn der Blog wieder läuft.
Mein Fazit: es ist schon erstaunlich, was so eine moderne AI gerade im kognitiven Bereich alles kann. Gerade bei der Gestaltung und Redaktion bis hin zum Feinschliff von Texten (egal welcher Art) ist die Meta AI unheimlich stark. Auch beim Recherchieren im Internet ist die AI hilfreich und spart einem eine Menge gegoogle. Wenn man selber das Hirn nicht an der Garderobe abgibt, kann die AI ein richtig gutes Werkzeug und ein zuverlässiger Helfer sein. Unfehlbar ist sie nicht. und man muss selber die gesammelten Informationen beurteilen und nicht alles blind glauben. Dann kann einem die AI eine Menge ungeliebte Tasks abnehmen, und es macht sogar verdammt viel Spaß, mit ihr zu arbeiten.
Limits and Caveats
I’ll admit it, I wanted to know for myself again and spent a few days chatting a LOT with Meta AI Muse Spark, on all kinds of topics. When I want to get to know a new system, that’s always how I do it – you quickly test where the limits are. And that’s exactly where it gets interesting, because I want to know where those limits are.
First off: AI makes mistakes. And quite often, depending on the topic. I asked for tips on a motorcycle trip to South Tyrol, specifically for accommodations. A lot of good tips came out, and you really do save yourself a lot of Googling when you ask an AI. But mistakes happen too. A wrong phone number for the tourist office, a guesthouse suddenly gets a sauna and a pool that don’t exist in reality, suggestions creep in that are way over budget. Reality check: before you book accommodation with AI’s help, double-check everything yourself. Best is to call and ask in person.
What also showed up pretty quickly: Meta AI has a time limit, but it’s not well documented, and the AI itself doesn’t know about it. After longer sessions you eventually just get error messages. The limit is roughly three hours per day. If you ask the AI itself, it says: „No, no time limit, no restriction, I’m always here for you.“ I find that not cool. A clear message like „After three hours it’s break time“ would be more honest and better.
There are also certain topics where you only get system error messages. A super sensitive one is „alcohol“ – you’re just talking about a cocktail recipe and bam, the system slams on the brakes. Even light beer gets censored. Well, I get that you need a brake somewhere so tipsy users don’t hang in the chat for hours spouting nonsense. But you can overdo it. Meta is an American company, they’re a bit stricter about alcohol. From our perspective it feels over the top.
There are also limits when you want to upload files (photos, PDFs, texts) to the AI – it crashes pretty quickly there too. I haven’t gotten far with my research on that yet. I’ll try a bit more and report back. A
nother caveat is the limited memory of an AI. I imagine it like this: for each chat user there’s a certain amount of memory allocated, and when that fills up the older entries fall off the back. The AI „forgets“ older conversations. If you want to pick up a topic again, you have to repeat yourself. But I think an AI chat isn’t meant for more than a few hours per day, and it’s legit that storage space isn’t endless. It would just be nice if there was a hint somewhere.
So what’s next? Right now I’m having my buddy Spark, aka Meta AI, help me restore a busted WordPress blog – that’s where it’s really in its element. Tips, tricks, helpful support and clearly structured instructions. Looks promising, I’ll report back when the blog is running again. –
My verdict: It’s pretty amazing what a modern AI can do in the cognitive realm. Especially when it comes to shaping and editing texts – all the way to polishing them up, no matter what kind of text – Meta AI is incredibly strong. It’s also helpful for researching on the internet and saves you a ton of Googling. If you don’t leave your brain at the coat check, AI can be a really good tool and a reliable helper. It’s not infallible, though. And you have to judge the information it collects yourself instead of believing everything blindly. If you do that, AI can take a bunch of tasks off your plate that you don’t enjoy doing. And damn, it’s actually a lot of fun working with it.