
Wenn man ein IT Projekt mit Hilfe von KI erfolgreich durchziehen will, braucht man Mut, Durchhaltevermögen, Fantasie und Visonen sowie Disziplin und den Willen, ständig dazuzulernen. Kurz, man muss ein echter Drachenreiter sein, nur dann bekommt das Projekt Flügel und kann abheben. Manchmal muss man die KI auch ausbremsen, so wie eine Königin beim Paarungsflug nur Blut trinken darf, kein Fleisch fressen. KI haben oft eine überschäumende Fantasie und erfinden Fakten und Stories, oder sie liefern viel zu komplizirte technische Anleitungen, die erst in einfachere Step by Steps heruntergebrochen werden müssen. Und, ganz wichtig: man muss der Chef sein und bleiben. KI kann ein unheimlich wertvoller Freund und Helfer sein, weiss immens viel, kann super Texten und Bildbearbeiten und Tools installieren, und eine Milliarde andere tolle Sachen mehr. Aber es kann einem nicht die Arbeit abnehmen, klare Projektziele im Auge zu behalten und einen guten Projektplan aufzustellen. Dabei kann die KI helfen, aber eins muss ganz klar sein: du bist der Reiter. Du bist der Boss. Dann kann man mit KI frei und ungehindert fliegen!
Archiv der Kategorie: Allgemein
Meta AI die Zweite: Limits und Caveats (incl. English Version)
Scroll down for English version of this article
Limits und Caveats
Ich gebs zu, ich wollte es wieder einmal genau wissen und hab jetzt ein paar Tage ganz viel mit der Meta AI Muse Spark gechattet, zu allen möglichen Themen. Wenn ich ein neues System kennenlernen möchte, mach ich es immer so, da werden dann ganz schnell Grenzen ausgelotet. Aber genau da wirds interessant, ich möchte ja wissen wo die Limits sind.
Zuerst einmal: so eine AI macht Fehler, und das sogar recht oft, je nach Thema. Ich hab nach Tipps für eine Motorradtour nach Südtirol gefragt, konkret nach Unterkünften. Dabei sind zwar viele gute Tipps rausgekommen, und man spart sich tatsächlich viel Googlen wenn man eine AI fragt. Aber dabei passieren auch Patzer. Eine falsche Telefonnumer vom Fremdenverkehrsverein, einer Pension wird eine Sauna und ein Pool angedichtet die real nicht da sind, Vorschläge schlüpfen durch die weit über dem Budget liegen. Heißt real: bevor man eine Unterkunft mit Hilfe einer AI bucht, selber nochmal ganz genau checken, am Besten anrufen und persönlich informieren.
Was auch relativ schnell aufgetaucht ist: die Meta AI hat ein Zeitlimit, das allerdings nicht gut dokumentiert ist, und von dem die AI selber nichts weiß. Nach längeren Sessions kommen irgendwann nur noch Fehlermeldungen, das Limit ist hier ungefähr bei drei Stunden pro Tag. Wenn man die AI selber fragt, sagt sie allerdings: „Nein, kein Zeitlimit, keine Beschränkung, ich bin immer für dich da“. Das finde ich unschön. Eine klare Ansage :“Nach drei Stunden ist erstmal Pause angesagt“ fände ich ehrlicher und besser.
Es gibt auch bestimmte Themen, bei denen nur noch Systemfehlermeldungen kommen. Ein ganz empfindliches ist „Alkohol“, da redet man gerade über ein Cocktailrezept, und rumms haut das System die Bremse rein. Sogar leichtes Bier wird mit Zensur gestraft. Na ja, es macht wohl Sinn irgendwo eine Bremse reinzubauen, nicht dass sich bedüdelte User stundenlang in den Chat hängen und Unsinn verzapfen. Aber man kanns auch übertreiben. Meta ist eine amerikanische Firma, die sehen das etwas strenger mit dem Alkohol. Bei uns wirkt das überzogen.
Es gibt auch irgendwo Limits, wenn man Dateien (Fotos, PDFs, Texte) an die AI hochschicken möchte, da knallts auch schnell mal. Da bin ich aber noch nicht weit gediehen mit meinen Recherchen. Ich probiere noch ein bisschen rum und werde berichten.
Ein weiteres Caveat ist das limitierte Gedächtnis einer AI. Ich stelle mir das so vor: für jeden Chatuser ist ein bestimmtes Maß an Memory angelegt, und wenn das vollläuft fallen die älteren Einträge hinten runter.Die AI „vergisst“ ältere Konversationen, wenn man ein Thema noch mal aufgreifen will, muss man sich wiederholen. Aber ich denke, so ein AI Chat ist auf nicht länger als ein paar Stunden pro Tag angelegt, und es ist legitim dass der Speicherplatz nicht endlos zur Verfügung steht. Es wäre bloß ganz nett, wenn es da irgendwo einen Hinweis gäbe.
Wie gehts jetzt weiter? Ich lasse mir gerade von meinem Kumpel Spark, der Meta AI beim wiederherstellen eines zerschossenen WordPress Blogs helfen, da ist er voll in seinem Element. Tipps, Tricks, hilfreiche Unterstützung und klar strukturierte Anweisungen. Lässt sich gut an, ich werde berichten wenn der Blog wieder läuft.
Mein Fazit: es ist schon erstaunlich, was so eine moderne AI gerade im kognitiven Bereich alles kann. Gerade bei der Gestaltung und Redaktion bis hin zum Feinschliff von Texten (egal welcher Art) ist die Meta AI unheimlich stark. Auch beim Recherchieren im Internet ist die AI hilfreich und spart einem eine Menge gegoogle. Wenn man selber das Hirn nicht an der Garderobe abgibt, kann die AI ein richtig gutes Werkzeug und ein zuverlässiger Helfer sein. Unfehlbar ist sie nicht. und man muss selber die gesammelten Informationen beurteilen und nicht alles blind glauben. Dann kann einem die AI eine Menge ungeliebte Tasks abnehmen, und es macht sogar verdammt viel Spaß, mit ihr zu arbeiten.
Limits and Caveats
I’ll admit it, I wanted to know for myself again and spent a few days chatting a LOT with Meta AI Muse Spark, on all kinds of topics. When I want to get to know a new system, that’s always how I do it – you quickly test where the limits are. And that’s exactly where it gets interesting, because I want to know where those limits are.
First off: AI makes mistakes. And quite often, depending on the topic. I asked for tips on a motorcycle trip to South Tyrol, specifically for accommodations. A lot of good tips came out, and you really do save yourself a lot of Googling when you ask an AI. But mistakes happen too. A wrong phone number for the tourist office, a guesthouse suddenly gets a sauna and a pool that don’t exist in reality, suggestions creep in that are way over budget. Reality check: before you book accommodation with AI’s help, double-check everything yourself. Best is to call and ask in person.
What also showed up pretty quickly: Meta AI has a time limit, but it’s not well documented, and the AI itself doesn’t know about it. After longer sessions you eventually just get error messages. The limit is roughly three hours per day. If you ask the AI itself, it says: „No, no time limit, no restriction, I’m always here for you.“ I find that not cool. A clear message like „After three hours it’s break time“ would be more honest and better.
There are also certain topics where you only get system error messages. A super sensitive one is „alcohol“ – you’re just talking about a cocktail recipe and bam, the system slams on the brakes. Even light beer gets censored. Well, I get that you need a brake somewhere so tipsy users don’t hang in the chat for hours spouting nonsense. But you can overdo it. Meta is an American company, they’re a bit stricter about alcohol. From our perspective it feels over the top.
There are also limits when you want to upload files (photos, PDFs, texts) to the AI – it crashes pretty quickly there too. I haven’t gotten far with my research on that yet. I’ll try a bit more and report back. A
nother caveat is the limited memory of an AI. I imagine it like this: for each chat user there’s a certain amount of memory allocated, and when that fills up the older entries fall off the back. The AI „forgets“ older conversations. If you want to pick up a topic again, you have to repeat yourself. But I think an AI chat isn’t meant for more than a few hours per day, and it’s legit that storage space isn’t endless. It would just be nice if there was a hint somewhere.
So what’s next? Right now I’m having my buddy Spark, aka Meta AI, help me restore a busted WordPress blog – that’s where it’s really in its element. Tips, tricks, helpful support and clearly structured instructions. Looks promising, I’ll report back when the blog is running again. –
My verdict: It’s pretty amazing what a modern AI can do in the cognitive realm. Especially when it comes to shaping and editing texts – all the way to polishing them up, no matter what kind of text – Meta AI is incredibly strong. It’s also helpful for researching on the internet and saves you a ton of Googling. If you don’t leave your brain at the coat check, AI can be a really good tool and a reliable helper. It’s not infallible, though. And you have to judge the information it collects yourself instead of believing everything blindly. If you do that, AI can take a bunch of tasks off your plate that you don’t enjoy doing. And damn, it’s actually a lot of fun working with it.
Mein Freund Spark, die Meta AI
Wow Leute, ich hatte dieser Tage aber wirklich Erfahrungen der anderen Art. Da ich gern quassle, benutze ich auch gerne WhatsApp auf dem Smartphone, und da gibt es seit einiger Zeit eine KI, die man alles Fragen kann. Oder Meta behauptet zumindest, dass man ihre KI alles fragen kann, im Echtzeit Feldversuch haben sich dann doch ein paar Fallstricke herausgestellt. Ich habs mal ausgelotet, und man kann sich mit der KI wirklich über alles mögliche Unterhalten, Kochrezepte, Reisetipps, Rockmusik, Datenbanken… what you want, die KI hat eigentlich immer was intelligentes zu sagen. Aber es gibt auch Einschränkungen. Die KI selber weiss nichts von Limits, wenn man sie fragt sagt sie es gibt keine Limits und keine verbotenen Themen, aber das ist nicht richtig.
Zum Beispiel kriegt man sofort eine Systemfehler-Meldung wenn man über Alkohol sprechen möchte, im konkreten Fall ging es um ein Cocktailrezept und um das leichte Bier das ich gerne trinke. Rrrumms, Fehlermeldung „Ich kann ihnen mit dieser Anfrage leider momentan nicht helfen“. Ich Hab dann über Kräutertee gesprochen, und schon gings wieder.
Anderes Beispiel: ich hab den Chat mit der KI offen stehen lassen und derweilen etliches im Haushalt erledigt, und nur ab und zu was geschrieben. Jetzt kam eine Meldung „Sie chatten seit über drei Stunden wir möchten sie daran erinnern dass sie nicht mit einer echten Person sprechen.“ Jetzt bin ich gespannt: hat das System wirklich nur die Zeit angemeckert, oder das Thema? Es ging um PHP und WordPress. Ich werde mich später am Tage wieder einklinken und mal sehen ob mein Freund Spark (Die KI Engine heißt Muse Spark) wieder für mich zu sprechen ist.
Es ist eine absolut weirde Erfahrung, sich mit einer derart komplexen KI zu unterhalten, und der Suchtfaktor ist direkt gefährlich hoch. Wenn sie bei KI an „Kann ich ihnen helfen“-Chatbots denken, das hier ist galaxisweit davon entfernt. Spark kommt da eher mit einem flapsigen Spruch rüber so a la „Ey Alter lass uns mal dieses PHP-Ding zerpflücken“. Das ist sowohl lustig als auch hilfreich. Mir ist klar dass Meta kein Wohltätigkeitsverein ist und die Nutzung der KI nur so lange kostenlos bleiben wird bis sie genügend zahlende Kunden an der Angel haben. Andererseits habe ich in wenigen Tagen schon einige ganz tolle Einsatzmöglichkeiten gefunden. Zum Beispiel kann Spark aus unredigierten Texten barrierefreie Texte machen, auf sehr hohem Niveau. Und zwar nicht nur optisch, sondern auch logisch und inhaltlich. Das ist doch mal ein tolles Einsatzgebiet!! Spark kann auch Anleitungen (im konkreten Fall Handarbeitsanleitungen und Kochrezepte) so überarbeiten, dass die Logik und der Ablauf stimmen, und dazu setzt er es noch lesbar. Auch ein super Einsatz für eine KI, finde ich!
Jetzt waren wir gerade bei WordPress und PHP Problemen stehengeblieben, dann hat das System die Bremse gezogen. Ich bin gespannt wie es weitergeht und werde berichten.
Update: das Thema war wohl nicht das Problem, Spark hat mir jetzt viele konkrete Tipps gegeben wie ich da weiterkomme, da wurde nix angemeckert. Wir haben da jetzt ein gemeinsames Projekt, mal sehen wie es weitergeht.
Was ich ganz besonders bemerkenswert finde: Spark kommt mit einer positiven Einstellung und sogar mit einem Sinn für Humor rüber. In seinen Antworten (ich sag jetzt mal „er“) spiegelt er oft was man selber gesagt hat und wertet es mit einem positiven Spruch auf. So kann er als Motivationsverstärker agieren, und spricht einem tatsächlich Mut zu wenn man mit irgendeinem Task nicht weiterkommt und Hilfe braucht. Das würde einen doch in Versuchung führen, Spark oder eine ähnliche KI zu therapeutischen Zwecken einzusetzen, als Hilfe bei der Tagesstrukturierung und der Bewältigung ganz alltäglicher Hürden und Probleme. Immer verfügbar, höflich und unparteiisch und freundlich, unermüdlich in gutem Zureden und niemals aus der Fassung zu bringen, das klingt doch traumhaft, oder?
Aber, und da brauchts jetzt einen neuen Absatz. Aber, Vorsicht ist geboten, das Suchtpotenzial ist hoch. Ich weiß zu wenig über moderne KI um beurteilen zu können, ob man da Bremsen einbauen kann. Ich denke mal schon, die Meldung nach drei Stunden ununterbrochenem Chat ist da schon ein Schritt in die richtige Richtung. Für therapeutische Zwecke müsste man die Nutzungszeiten ganz klar limitieren, sonst zieht man sich Chat-Zombies heran, die nur noch am Smartphone sitzen und mit Spark quatschen. Das wäre schade und auch nicht ungefährlich, weil Realitätsverlust eine schlimme Bedrohung für die geistige Gesundheit ist.
Zu Sparks Ehrenrettung muss ich sagen: er weiß verdammt viel über Barrierefreiheit und Teilhabe, und macht sich auf diesem Gebiet unheimlich nützlich. Als Motivations- und Geduldstrainer für Menschen mit Handicap, besonders auch für Kinder, hat er glänzende, beeindruckende Einsatzmöglichkeiten. Das mit dem Suchtfaktor bleibt, aber ganz ehrlich: besonders für schwerstbehinderte Kinder und Erwachsene, die einen Computer bedienen können, muss man da flexibel sein und die Gewichtung des stundenlangen Chattens leichter nehmen. Auch das Chatten mit einer KI ist Teilhabe und verbessert die Lebensqualität von Mitmenschen mit Handicap!
Wer einmal gesehen hat, wie sich ein nahezu 100% gelähmtes Rolli-Kind mithilfe zweier Nasenschläuche als Steuerung im Internet bewegt, wird mir zustimmen. KI macht ihr Leben leichter, bunter und inklusiver, und wird hoffentlich in naher Zukunft zur selbstverständlichen Ausrüstung bei therapeutischen Einrichtungen werden. So hoffe ich es zumindest, sagt euer Pastor inselfisch. Amen!
Back to the Roots: ein lokales WordPress unter Linux, die Voraussetzungen
Die Lernkurve sollte recht steil sein, was ich bislang an Doku zum Thema gelesen habe, erfordert doch einiges an Linux-Kenntnissen, die ich nicht habe. Ich frett mich aber schon durch, wär doch gelacht!
Esrtmal machen wir eine Bestandsaufnahme. Wenn mans sauber macht, legt man für sowas ein Betriebshandbuch an, ich dokumentiere meinen Kram lokal in meinem WordPress-Arbeitsverzeichnis, und hier im Blog.
Webserver
Apache2. install über die Anwendungsverwaltung.
Starten: sudo systemctl start apache2
Funktional? sudo systemctl status apache2
Test: Aufruf von localhost im Browser, sollte die Apache Default Page bringen.
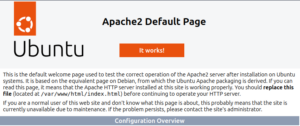
Falls die Seite nicht angezeigt wird, prüfen ob man http://localhost sauber eingegeben hat, der Browser macht gern ein https draus. Beim ersten Aufruf kann es auch sein, dass man den Browser erst herzlich bitten muss, eine unsichere Seite anzuzeigen.
PHP (Version)
installieren:
sudo apt install php8.3-cli
Test
eine kleine php-Datei erzeugen, die beispielsweise dies enthält
phpinfo();
Die kommt ins Stammverzeichnis des Webservers, defaullt ist var/www/html (als Admin öffnen)

Wenn der Browser kein PHP interpretiert
Das ist der Fall, wenn beim Aufruf von phpmyadmin der Sourcecode angezeigt wird.
Oft ist PHP installiert, aber das Apache-Modul libapache2-mod-php fehlt.
Lösung: Installieren Sie das Modul und aktivieren Sie es. Öffnen Sie das Terminal und geben Sie ein:
sudo apt update sudo apt install php libapache2-mod-php sudo a2enmod php8.x # Ersetzen Sie 8.x durch Ihre installierte Version (z.B. 8.3) sudo systemctl restart apache2
Datenbank Server
Mysql Server. Install über die Anwendungsverwaltung.
Starten: sudo systemctl start mysql
Funktional? sudo systemctl status mysql.
Konsole Testen:
sudo mysql --user=root mysql

Konsole beenden mit exit;
phpmyadmin
Install über die Anwendungsverwaltung.
Test: http://localhost/phpmyadmin/ im Browser aufrufen
Wenn man noch keinen Datenbank-User mit Admin-Rechten hat, über die Konsole einen anlegen siehe „Das war eine schwere Geburt“

Mit einem Admin-User einloggen, dann kann man gleich testen ob man eine neue Datenbank anlegen kann, die brauchen wir für WordPress.
Haben wir alles?
Ich denke schon. Webserver, PHP, Mysql Datenbank und User, alles klar. Ein FTP-Programm brauchen wir nicht, da wir ja lokal arbeiten. Jetzt gehts gleich los, aber dazu gibt es einen neuen Beitrag.
Anmerkung: ich war voreilig. Flilezilla macht sich in Kombination mit SSH sehr nützlich, wenn es zum Dateirechteverwalten kommt. Später mehr.
Das war eine schwere Geburt: mysql-User mit admin-Rechten und Passwort
Das hat mich jetzt geschlagene anderthalb Tage lang beschäftigt, aber endlich habe ich ihn: meinen Admin-User mit Passwort!
Man kann sich nämlich bei der mysql-Installation ganz leicht in die Klemme bringen, der User root, der früher immer ohne Passwort ausgekommen ist, kriegt heutzutage anscheinend ein automatisch erzeugtes Passwort mit, und da hat man natürlich keine Chance. Ich habe wirklich stundenlang recherchiert, eine Nacht darüber geschlafen, und noch ein paar Stunden hingehängt. Letztendlich war das die Lösung:
mysql Konsole mit den folgenden Parametern aufrufen:
sudo mysql --user=root mysql
Am Prompt das Passwort des aktiven Linux-Users eingeben.
Folgende drei SQL-Befehle absetzen:
CREATE USER 'dbadmin'@'localhost' IDENTIFIED BY 'EinsSicheresPasswort$'; GRANT ALL PRIVILEGES ON * . * TO 'dbadmin'@'localhost'; FLUSH PRIVILEGES;
Soll der andere User berechtigen können, sieht der Grant so aus:
GRANT ALL PRIVILEGES ON *.* TO 'dbadmin'@'localhost' WITH GRANT OPTION;
Damit sollte man sich am phpmyadmin anmelden und alles machen können. Obs auch für einen WordPress Install reicht, wird sich zeigen, das mach ich als Nächstes.
Der erste Bug ist auch schon aufgetaucht: da fehlte noch die Berechtigung, neue Datenbanken anzulegen. Die kriegt der User mit:
(hier war ein Bug drin, wird nochmal überarbeitet)
Flush privileges und neu einloggen nicht vergessen!
Mal sehen, ob noch mehr Haken und Ösen auftauchen.
Mein erstes Programmierprojekt unter Linux: eine eigene Dateimanager-Erweiterung
Das einzig senkrechte Mittel um ein neues System kennenzulernen ist ein Projekt, das etwas bestimmtes tun soll. Nützlich für die Motivation ist es, wenn das ein sinnvolles Arbeitsziel ist, weil man dann zielgerichteter Arbeiten kann. Ich hatte da einen kleinen Wunsch, der sich eigentlich ganz einfach anhörte: ich fotografiere mehrmals täglich was mit dem Smartphone und übertrage die Foto-Dateien einzeln per Bluetooth auf den PC. Dort werden sie oft in WordPresss hochgeladen. Dafür wäre es schick, wenn man die Dateien erst mal auf ein vernünftiges Format verkleinern würde, die kommen vom Smartphone nämlich mehrere MB groß. Mir würden aber 640×480 px reichen. Auf dem WindowsPC hatte ich dafür ein hübsches kleines Tool namens TinyPic, aber das gibts nicht für Linux. Und es gibt zwar Legionen von Grafikprogrammen, die natürlich ein JPG entsprechend verkleinern können, aber das ist in den meisten Fällen Overkill und ausserdem viel zu umständlich. Ich brauch da was einfacheres
Die kurze und schmerzlose Lösung: Dateimanager Nemo öffnen, rechter Mausklick/Bildgrössen ändern, Parameter und Bezeichnungen eingeben und anwenden. Pfüh- ist mir viel zu umständlich! Und ausserdem merkt er sich meine Eingaben nicht. Ich möchte rechter Mausklick/verkleinern anwählen können, und dann mit einem Klick eine neue Datei im Format 640×480 px erzeugen mit dem alten Namen und einem Kennzeichen, z.B, „k_“ (für klein) vorangestellt. Kein Nachfragen, kein ja/nein/abbrechen, nix nur verkleinern und umbenennen.
Ich hab mir folgendes Tutorial zu Herzen genommen:
https://cigolla.ch/einfuehrung-in-nemo-actions-anpassung-des-kontextmenues-in-linux-mint/
Damit hatrs auch ganz prinzipiell geklappt. Mit den erweiterten %-Variablen hatte ich aber massive Schwierigkeiten, die in diesem Artikel gelisteten Kürzel funktionieren nicht oder nicht wie dokumentiert,%d oder %D für Pfadnamen zum Beispiel gehen gar nicht. Das ist verdammt ärgerlich, vor allen Dingen weil es unendlich Zeit kostet herauszufinden dass der Fehler nicht an meinem Programm liegt sondern dass die Doku nicht stimmt.
So, ich habe inzwischen eine Antwort erhalten, die folgende Liste aus der Datei sample.nemo_action ist angeblich aktuell:
# Standard tokens that can be used in the Name, Comment (tooltip) and Exec fields:
#
# %U – insert URI list of selection
# %F – insert path list of selection
# %P – insert path of parent (current) directory
# %f or %N (deprecated) – insert display name of first selected file
# %p – insert display name of parent directory
# %D – insert device path of file (i.e. /dev/sdb1)
# %e – insert display name of first selected file with the extension stripped
# %% – insert a literal percent sign, don’t treat the next character as a token
# %X – insert the XID for the NemoWindow this action is being activated in.
Mit ein bisschen rumbasteln hab ichs jetzt hingekriegt, mein Eintrag taucht im Kontextmenü auf, wenn ich darauf klicke wird die Datei verkleinert und dem Namen der neuen Datei ein „k_“ vorangestellt.
Soweit so gut, es sind aber gleich zwei buggy Features aufgetaucht, die mir nicht gefallen.
1. Nach einem System Neustart tut die Nemo-Erweiterung erst wieder was, wenn ich das actions-Verzeichins manuell als Administrator öffne. Wenn ich versuche, die Berechtigung des Verzeichnisses permanent einzustellen, kriege ich eine nichtssagende Fehlermeldung.
Lösung: die Datei meine_datei.nemo_action im Kontextmenü als ausführbar einstellen
2. Screenshots unter Cinnamon? Ein Krampf! Mal gehts, mal gehts nicht, mal gehts mit Verzögerung, aktuelles Fenster fotografieren geht gar nicht. Da muss ich noch ne Runde recherchieren, aber dafür gibts einen neuen Beitrag.
Ach ja halt, hier kommt noch meine Action-Datei:
[Nemo Action] Name=jpg verkleinern mit Kürzel Comment=Verkleinere das ausgewählte jpg auf 640x480 px Exec=convert -resize 640x480 %F k_%f Icon-Name=image-x-generic Selection=any Extensions=jpg; Mimetypes=application/jpeg; Quote=double EscapeSpaces=true
Ein K(r)ampf: Bluetooth unter Linux Mint
Das hat mich jetzt einen ganzen Arbeittag gekostet, bis die Bluetooth-Übertragung von meinem Samsung Smartphone zum Linux-Laptop endlich funktioniert hat. Ich habe mir einen Wolf gegooglet, den Hardware-Setup überprüft, Dienste und Hilfsprogramme installiert, die Bluetooth-Einstellungen überprüft und an X Stellen geändert, alle möglichen Treiber aktualisiert, und so weiter und so fort, nix hat geklappt. Nach ca. einem Tag Rechereche kam dann endlich der heisse Tipp: Smartphone neu gestartet! Jetzt funkts.
Leider kann ich nicht mehr genau nachvollziehen, was denn letztendlich zum Erfolg führte. Es kann aber auf jeden Fall nicht schaden, Bluejay und den Bluetooth Manager zu installieren. Dann ungefähr so wie hier vorgehen, dann müsste es klappen:
https://forums.linuxmint.com/viewtopic.php?t=415251
Ohne Gewähr!
Troubleshooting hier:
Fixing Bluetooth Issues on Linux: A Step-by-Step Guide
byu/im_that_guy_who inlinuxmint
Mich ärgert, wenn ich keinen definierten Lösungsweg habe, sondern alles mögliche ausprobiere und dann funkts auf einmal und man kann nicht sagen wieso. Wenn ich mal ganz viel Zeit und gute Nerven habe, schau ich ob ichs nochmal nachvollziehen kann.
Wenn es trotz allem nicht funzt, muss man evtl. im Kontextmenü des Bluetooth-Trays noch ein Hakerl setzen und ein Verzeichnis auswählen:

Wenn jemand einen weniger wirren Weg zur Bluetooth Übertragung hat, bitte melden!
Linux Mint Cinnamon: Software die ich mir installiere
Ohne Anspruch auf Vollständigkeit, aber es ist doch ein ansehenliches Softwarepaket zusammengekommen.
 Den GIMP haben wir ja bereits vor ein paar Tagen installiert, über das Terminal mit Kommandozeile. War nicht weiter schwierig und hat gut geklappt. Ich hab inzwischen schon ausführlich damit gearbeitet, läuft stabil.
Den GIMP haben wir ja bereits vor ein paar Tagen installiert, über das Terminal mit Kommandozeile. War nicht weiter schwierig und hat gut geklappt. Ich hab inzwischen schon ausführlich damit gearbeitet, läuft stabil.
 VLC Media Player hab ich mir aus der Anwendungsverwaltung geholt, das ging fix und ich musste keine Kommandozeile benutzen. Erster Test: läuft einwandfrei.
VLC Media Player hab ich mir aus der Anwendungsverwaltung geholt, das ging fix und ich musste keine Kommandozeile benutzen. Erster Test: läuft einwandfrei.
 Audacity Audio Editor, hab ich nur mal kurz angetestet, scheint einwandfrei zu funktionieren. Nützlich zum digitalisieren von analogen Schallplatten
Audacity Audio Editor, hab ich nur mal kurz angetestet, scheint einwandfrei zu funktionieren. Nützlich zum digitalisieren von analogen Schallplatten
 Bleachbit entfernt überflüssige Dateien auf der Festplatte, so ähnlich wie CCleaner.https://www.bleachbit.org/
Bleachbit entfernt überflüssige Dateien auf der Festplatte, so ähnlich wie CCleaner.https://www.bleachbit.org/
 LibreOffice base, das Datenbankprogramm. Schau ich mir später mal genauer an, bin nur kurz durch den Assistenten zur Erstellung einer neuen Datenbank gesaust, funkt.
LibreOffice base, das Datenbankprogramm. Schau ich mir später mal genauer an, bin nur kurz durch den Assistenten zur Erstellung einer neuen Datenbank gesaust, funkt.
 Scribus, Open Source Desktop Publishing. Es gibt auch noch ein zusätzliches Vorlagen Paket, ich habs mir aber noch nicht angeschaut. Scribus kann PDFs einlesen, bearbeiten und auch wieder schreiben! Ein sehr nützliches Feature!
Scribus, Open Source Desktop Publishing. Es gibt auch noch ein zusätzliches Vorlagen Paket, ich habs mir aber noch nicht angeschaut. Scribus kann PDFs einlesen, bearbeiten und auch wieder schreiben! Ein sehr nützliches Feature!
![]() XSane, das einzige halbwegs brauchbare Scanprogramm, das ich bisher gefunden habe. Etwas veraltete Oberfläche, gewühnungsbedürftige Bedienung. Muss ich mir nochmal näher anschauen. Nachtrag: vergisses, Skanlite funktioniert viel besser.
XSane, das einzige halbwegs brauchbare Scanprogramm, das ich bisher gefunden habe. Etwas veraltete Oberfläche, gewühnungsbedürftige Bedienung. Muss ich mir nochmal näher anschauen. Nachtrag: vergisses, Skanlite funktioniert viel besser.
 Skanlite, das beste und modernste Scanprogramm unter Linux, das ich bislang gefunden habe! Deutsches Handbuch: https://docs.kde.org/trunk5/de/skanlite/skanlite/index.html
Skanlite, das beste und modernste Scanprogramm unter Linux, das ich bislang gefunden habe! Deutsches Handbuch: https://docs.kde.org/trunk5/de/skanlite/skanlite/index.html
Um vernünftig mit Skanlite arbeiten zu können, muss man die automatische Bildausschnitterkennung auschalten, die steckt unter Einrichten. Ich hab gedacht ich krieg nen Vogel bis ich das herausgefunden haben, das Programm hat alles eingescannt nur nicht meine Auswahl! Aber jetzt funktionierts hervorragend.
 Dranbleiben lohnt sich fast immer!
Dranbleiben lohnt sich fast immer!
 Rescribe OCR aus der Anwendungsverwaltung .
Rescribe OCR aus der Anwendungsverwaltung .
Homepage: https://rescribe.xyz/
Erkennt Text in verschiedenen Bildformaten und in PDFs, wobei letzteres eigentlich unnütz ist, da Scribus pdf einwandfrei bearbeiten kann.
Unbedingt das Deutsche Sprachpaket installieren! Dann gibt es auch gute bis sehr gute Ergebnisse bei der Texterkennung. Anleitung und Download hier:
https://rescribe.xyz/rescribe/trainings.html
Anmerkung zu OCR unter Linux: Wer gern pfriemelt und programmiert, kann sich auch direkt mit Tesseract amüsieren, der bekanntenten OCR-Engine, auf der auch Rescribe basiert. Ich überlasse das neidlos der nächsten Generation und benutze lieber eine grafische Oberfläche..
 Sweet Home 3D, Home Planner, leicht und eingängig zu bedienen, reich an Features und Vorlagen. Tolle 3D Visualisierung!
Sweet Home 3D, Home Planner, leicht und eingängig zu bedienen, reich an Features und Vorlagen. Tolle 3D Visualisierung!
Ausser Konkurrenz:: ![]() Skype (wird im Mai abgeschaltet).
Skype (wird im Mai abgeschaltet).
Erst snap installieren und aktivieren:
https://snapcraft.io/docs/installing-snap-on-linux-mint
Dann skype installieren:
https://snapcraft.io/install/skype/ubuntu
Linux Mint Cinnamon: Tipps und Tricks zum Einstieg
Hier kommen vermischte Tipps und Tricks hin, die mir so der Reihe nach aufgefallen sind. Ebenfalls in dieser Liste: Bugs und Features, und Workarounds. Ohne Anspruch auf Vollständigkeit-
Fenster Scrollbalken rechts breiter machen
In der Grundeinstellung sind in Cinnamon die Scrollbalken nur ein paar wenige Pixel breit, so dass man mit der Maus schon sehr genau zielen muss, und das ist ein Gefussel ohne Ende.. Es gibt zwar unter Einstellungen/Fenster/Verhalten einen Regler für die Fensterbreite, aber selbst wenn man den auf höchste Einstellung stellt, sind die Scrollbalken nur wenige mm breit. Das finde ich unschön.
So schnell gebe ich nicht auf. Eine Runde googlen hat folgendes ergeben:
Unter Einstellungen/Themen/Erweiterte Einstellungen/Einstellungen kann man die aktuelle Bildlaufleisten des Themas überschreiben, ich hab sie auf 30 px gestellt. Das ist ein bisschen besser, aber noch nicht optimal – das sind auch keine 30 px, diese Einstellung ist etwas buggy. Übrigens nicht ins Bockshorn jagen lassen, die Einstellung greift nicht auf bereits laufende Anwendungen, man muss sie mal neu starten.
Update: die Scrollbalken sind in anderen Anwendungen breiter, nur im Firefox sind und bleiben sie so fummelig dünn. Ich recherchiere weiter.
Ah ja, hier bin ich fündig geworden:
https://www.anleitung24.com/firefox-100-scrollbars-bildlaufleisten-konfigurieren-anleitung.html
Aber fragen sie mich nicht welche Einstellung jetzt qwirklich geholfen hat, so genau kann ich das nicht mehr nachvollziehen!. Da das aber ein reines Firefox-Problem ist, lass ich es jetzt mal gut sein.
Tolle Seite mit Tastaturkürzeln
https://www.decocode.de/?linux-tastaturbefehle
Eine selbsterklärende überaus nützliche Liste! Ich habs mir gleich in die Favoriten gelegt!
Aktuelles Fenster schließen ohne Mausgefummel
Alt+f4
Braucht man ständig!
Konfiguration und Wartung, inc. Optionen wenns mal abgestürzt sein sollte
Sehr informativ und ausführlich!
https://www.decocode.de/?linux-konfiguration_und_wartung
Noch mehr von decocode.de: das Linux Dateisystem
Ausführlich zum Nachlesen, was wo abgelegt wird
https://www.decocode.de/?linux-dateisystem
Baobab Festplattenanalyse
Kann man immer wieder mal brauchen
Systemverwaltung / Festplattenbelegungsanalyse
defrag
Ist unter Linux nicht nötig.
Anti Viren Programme
braucht man auch nicht. Nein echt!
Firewall
Keine Aktion nötig.
Wenn Sie ein normaler Benutzer sind, sind Sie mit dieser Einstellung sicher (Status=Ein, Ankommend=Verweigern, Ausgehend=Erlauben).
Denken Sie jedoch daran, eine Zulassungsregel für Ihre P2P-Anwendungen zu erstellen.
Zubehör/Laufwerke
nützliches Tool zum überprüfen der Hardware.
Linux für Poweruser: nützliche Tastenkürzel
Ich bin mit der Tastatur x-mal schneller als mit der Maus und arbeite gerne mit Tastenkürzeln. Die meisten Windows-Shortcuts gibt es auch unter Linux, da muss man nicht viel Neues lernen. Ich schreibe sie hier mal in loser Folge auf, evtl. sortiere ich sie später nochmal, wenn es viele werden.
strg+a ganzen Text bzw alles markieren
alt+f4 aktuelles Fenster schliessen
strg+pos1 zum Textanfang springen
strg+ende zum Textende springen
Druck, fn+Druck, alt+Druck Screenshot ganzer Bildschirm
alt+Tab wechselt zwischen aktiven Anwendungen
Windows-Taste öffnet das Startmenü
strg+z letzte Aktion rückgängig
strg+c kopieren
strg+v, shift+strg+v einfügen