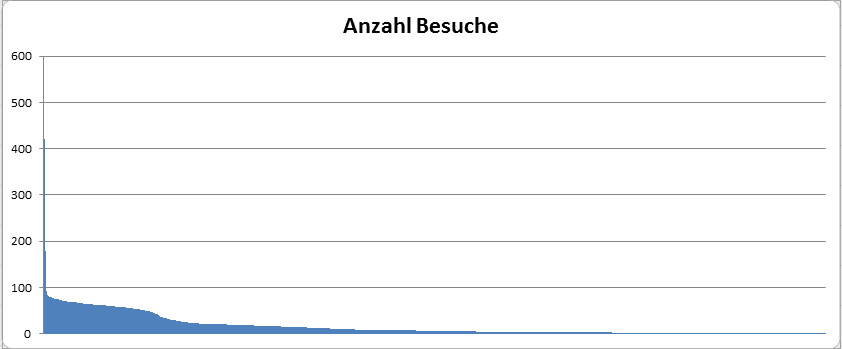
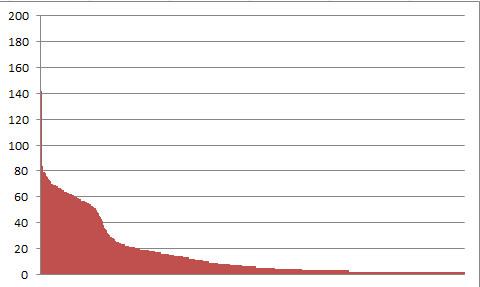
Tscha, der nette kleine Visitor Counter auf meinen Webseiten musste leider weg, weil der die IP-Adressen der Besucher bunkert, und das ist nach der neuen Datenschutz-Verordnung nicht mehr erlaubt, IP-Adressen zählen als schutzwürdige persönliche Daten und dürfen nicht mehr ungecrypted gespeichert werden. Mich interessiert aber trotzdem, was die Besucher auf meinen Seiten anzieht, und ich hab mir fürs Inselfisch-Kochbuch eine „kleine“ Alternative gebastelt.
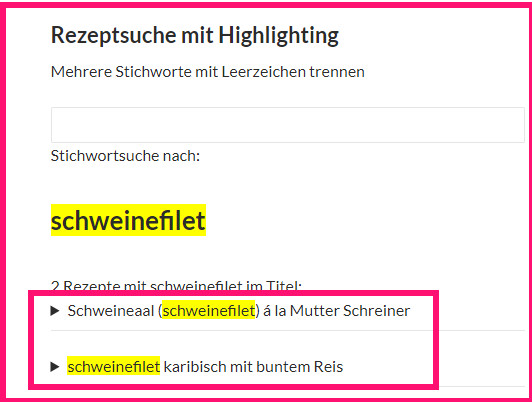
Rezeptecounter ganz minimalistisch
Eigentlich ist es für mich am Interessantesten, welche Rezepte am öftesten aufgerufen werden, die Aufrufe der wenigen statischen Seiten interessieren mich eher weniger. Das könnte ich mir zwar aus den Logfiles meines Providers herausfieseln, aber der Aufwand ist doch relativ hoch. Das geht auch einfacher, dachte ich mir, da klemme ich eine kleine PHP-Funktion ans Ende jedes Rezeptes und schreibe mir die Aufrufe in eine eigene Tabelle. Damit habe ich eine prima kleine Rezepte-Hitparade und kann z.B. die 10 beliebtesten Rezepte ausgeben oder sonstwas damit anstellen.
Damit kann ich in der single.php ansetzen und mir da einen kleinen Zähler einbauen, der mir in die Datenbank bunkert wie oft das jeweilige Rezept schon aufgerufen wurde. Die Funktion kommt in einen Shortcode, und der wiederum kommt in ein Plugin, der Plugin-Aufruf kommt ins Child-Theme in die single.php nach dem Content.
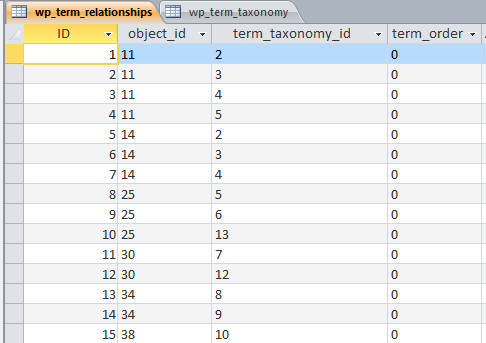
Die Tabelle counter
ist ganz einfach strukturiert:
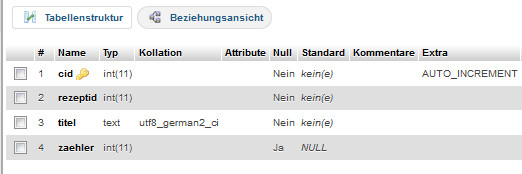
tabelle_counter
Eine Autowert-ID, und drei Felder für Rezept-ID, Titel und der Zähler für die Aufrufe, das wars schon.
Die Funktionalität des Shortcodes
… ist auch nicht weiter kompliziert. Ich hole mir ID und Titel des aktuellen Rezeptes ab und gehe mit der ID auf die Tabelle counter. Falls die ID da noch nicht vorhanden ist, mache ich einen Insert, falls sie schon da ist, setze ich den Zähler um eins hoch und mache einen Update. Das wars schon!
function el_rezeptcounter() {
if(is_single()) {
//id und titel abholen
global $wpdb;
$akt_id = get_the_id();
$akt_titel = get_the_title();
//Bisherige Anzahl holen
$alleposts = $wpdb->get_results( "SELECT * from counter where rezeptid = ".$akt_id."");
$anzahl = $wpdb->num_rows;
$zaehler = 0;
foreach($alleposts as $einpost){
$zaehler = $einpost->zaehler;
}
echo "Dieses Rezept wurde bisher ".$zaehler." mal aufgerufen";
if($anzahl == 0){
//Neuen Aufruf eintragen
$wpdb->insert('counter', array(
'rezeptid' => $akt_id,
//Sonderbehandlung für - und " usw.
'titel' => html_entity_decode($akt_titel),
'zaehler' => 1
));
}else{
//Zähler updaten
$zaehler = $zaehler +1;
$wpdb->update(
'counter',
array(
'zaehler' => $zaehler // int
),
array( 'rezeptid' => $akt_id )
);
}
} //End von if( is_single)
}
add_shortcode ('counter', 'el_rezeptcounter');
Dabei kann man sich überlegen, ob man bei der Ausgabe der bereits erfolgten Aufrufe bei 0 oder bei 1 das zählen anfängt, das ist Geschmackssache. Korrekter ist es wahrscheinlich, mit dem aktuell erfolgten Aufruf bei 1 anzufangen, Dann sähe die Zeile mit dem Zähler für die Ausgabe so aus:
if ($o_zaehler == ''){$zahl = 1;}else{$zahl = $o_zaehler+1;}
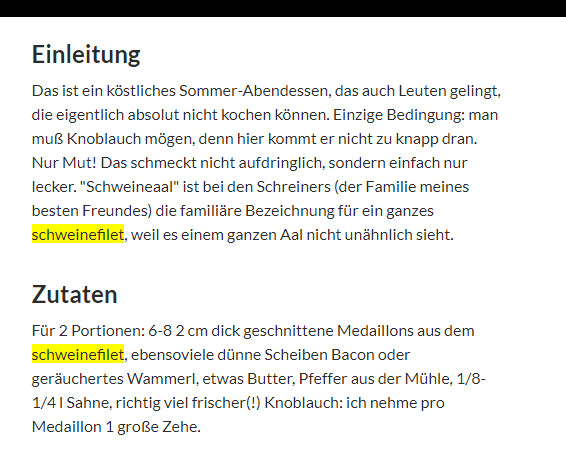
Den html_entity_decode($akt_titel) brauchts, weil ich in meinen Titeln auch mal Zeichen wie – oder “ verwende, damit das in der Datenbank sauber ankommt.
Der Aufruf des Shortcodes in der single.php
… wird nach Wunsch vor oder nach dem Content platziert:
<!--Shortcode für den Rezepte-Counter-->
<?php echo do_shortcode("[counter]"); ?>
Und so sieht die Ausgabe aus:
4malaufgerufen
Update und Tipp:
Man kann die Counter-Funktionalität statt in einen Shortcode auch in einen Filter packen. Ich bin zwar mit komplexen Filtern in WordPress schon manchmal auf die Nase gefallen, aber hier scheint es stabil zu funktionieren. Der Code bleibt gleich, nur setze ich dann den Filter auf the_content:
function el_rezeptcounter($content) {
if(is_single()) {
...
...(Hier kommt der Code wie oben)
...
.
} //End von if( is_single)
return $content;
}
add_filter( 'the_content', 'el_rezeptcounter' );
Damit kann man sich den Umbau der single.php sparen.
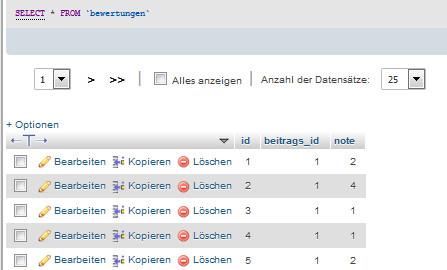
Die Counter-Tabelle
Die Tabelle counter ist sehr übersichtlich, man kann sie sich gleich mal nach dem Zähler sortieren und sieht sofort, welche Rezepte die meisten Aufrufe haben.
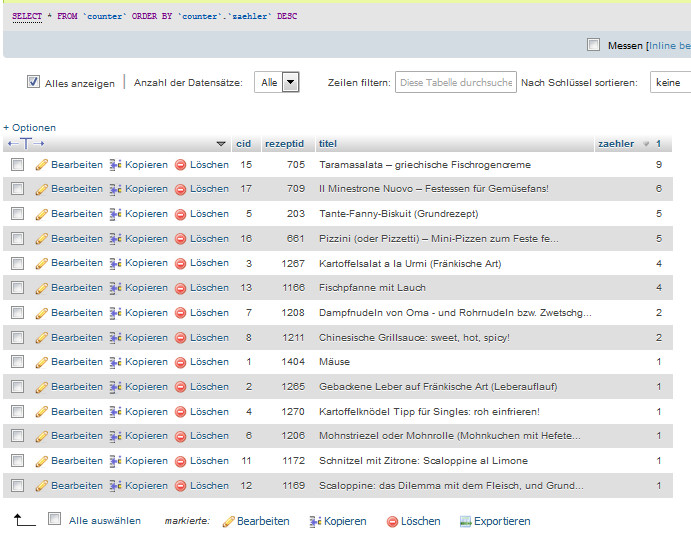
counter_mit_eintraegen
Das kann man natürlich hübsch für eine Ausgabe z.B. als Rezept-Hitparade verwenden, dafür basteln wir uns:
Den Hitparaden-Shortcode
kann man sich selber dahin platzieren wo man ihn am liebsten hat, die Konstruktion ist denkbar einfach:
function el_rezepthitparade(){
global $wpdb;
echo "<h2>Die beliebtesten Rezepte</h2>";
$alleposts = $wpdb->get_results( "SELECT * FROM counter ORDER BY zaehler DESC");
foreach ($alleposts as $einpost){
echo $einpost->titel." (".$einpost->zaehler.")<br>";
}
}
add_shortcode('hitparade','el_rezepthitparade');
Ausgabe:

diebeliebtestenzezepte
Man kann jetzt noch die Anzahl der ausgegebenen Zeilen mit einem LIMIT steuern, aber man kann auch noch ganz was anderes machen, nämlich das Ganze in ein Widget packen und die Anzahl der auszugebenden Zeilen als Benutzereingabe abfragen. Aber das ist dann doch recht aufwendig, ich nehme hier mal lieber eine kleine Lösung:
Shortcode in Text-Widget packen
Dafür zieht man sich einfach ein Text-Widget an die passende Stelle und gibt hier nur den Shortcode ein, z.B.
Die beliebtesten Beiträge
Ein kleiner Chat in PHP – wieder mal was für Minimalisten (7509)
Kraut und Rüben auf der Datenbank: wo wooCommerce die Produktdaten speichert (4668)
Kontrastfarbe automatisch berechnen mit jquery/Javascript (4562)
Noch mehr postmeta: benutzerdefinierte Felder in wooCommerce (4527)
Schmankerl für alte Datenbanker: Zugriff auf externe Daten mit dem wpdb-Objekt (4350)
Joomla-Template 2: die index.php (4334)
Alphabetische Paginierung aus Array: die Tücken des PHP-sort() (3744)
Ein einfaches Joomla-Template erstellen (3037)
HTML5 Datalist Value – ganz so einfach ist es nicht (3005)
PHP 5.6 forever? (2990)
. Wenn das nicht funktioniert, sind die Shortcodes für Textwidgets noch nicht enabled, das geht aber mit einer Zeile im Plugin oder in der functions.php des Child-Themes:
add_filter('widget_text', 'do_shortcode');
Das sollte es gewesen sein. Wir hübschen die Ausgabe noch mit Links zu den Rezepten auf, das ist auch nicht weiter schwierig, wir haben ja die IDs und packen das mit in den foreach:
foreach ($alleposts as $einpost){
$pfad = get_the_permalink($einpost->rezeptid);
echo "<a href = '".$pfad."'>".$einpost->titel."</a> (".$einpost->zaehler.")<br>";
}
Jetzt ist es aber schön genug!
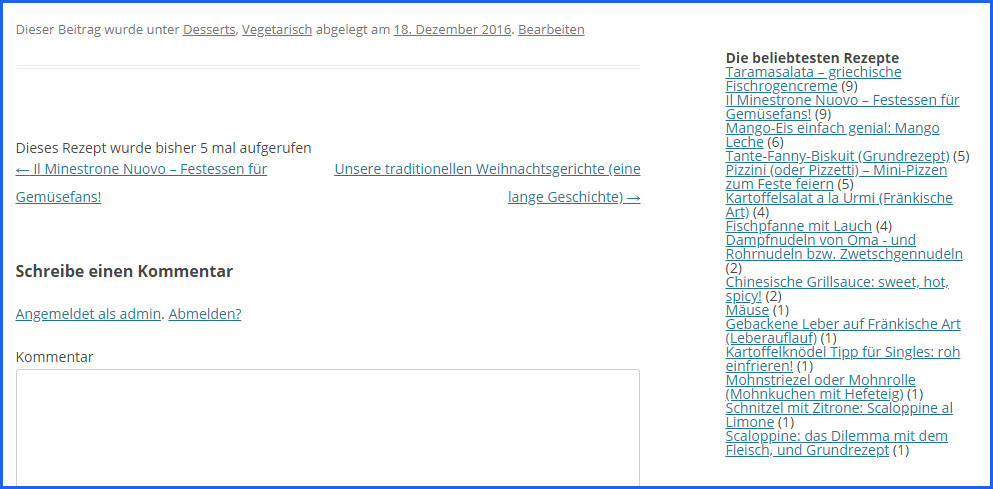
widgetmit_links
Nachschlag für WordPress-Puristen
Ich bin darauf hingewiesen worden, dass man die Anzahlen der Rezeptaufrufe auch in der wp_options speichern könnte, das wäre die sauberere Lösung. Ja bittesehr, kann man, ist nicht besonders schwierig. Man muss sich halt überlegen, wie man die Options benennt, damit man sie nachher auch auswerten kann. Ich hab da mal einen Versuch gemacht und die Optionsnamen nach dem Muster zaehler_[beitragsid] zusammengeschraubt. D:ie Funktion zum Wegschreiben ist recht übersichtlich geworden:
function el_rezeptcounter() {
if(is_single()) {
//id und titel abholen
$akt_id = get_the_id();
$akt_titel = get_the_title();
//option nachschauen
$o_zaehler = get_option('zaehler_'.$akt_id.'');
if ($o_zaehler == ''){$zahl = 0;}else{$zahl = $o_zaehler;}
echo "Dieses Rezept wurde bisher ".$zahl." mal aufgerufen";
if($o_zaehler == ''){
update_option('zaehler_'.$akt_id, 1);
}else{
//Zähler updaten
$o_zaehler = $o_zaehler +1;
update_option('zaehler_'.$akt_id, $o_zaehler);
}
} //End von if( is_single)
}
Man kann hier ohne Gefahr update_option() verwenden, da es eine Option einfach neu anlegt, falls sie noch nicht vorhanden sein sollte. Das funktioniert soweit ganz gut und hat hier zum Testen etliche Einträge korrekt in meiner wp_options hinterlassen:

wp_options
Eine Übersicht bekäme man im ersten Ansatz mit diesem Select heraus:
( "SELECT * from wp_options where option_name like 'zaehler_%'
ORDER BY option_value DESC");
Was mir an dieser Lösung allerdings nicht gefällt: wie wertet man das jetzt aus und kriegt die Rezepttitel mit zu den Zählerständen? Als Optionsnamen nur die Rezept-ID allein (ohne das zaehler_ vorneweg) zu vergeben wäre ein Lösungsansatz, aber das gefällt mir nicht so recht.
Man könnte natürlich in den option_value ein Array mit ID, Zähler und Titel packen und WordPress die Daten serialisieren lassen (hier bei wpengineer.com ein nettes Tutorial zu dem Thema), aber das ist mir eigentlich zu umständlich, da hat man dann das G’frett damit, die Daten wieder einzeln rauszufieseln. Da bleibe ich lieber bei meinem „kurzen Dienstweg“ mit der eigenen Tabelle.
Update
Ich bin gefragt worden, ob ich nicht ein Beispiel für das Wegschreiben der Options als Array bringen könnte. Ja OK, machen wir, aber dazu gibts einen neuen Beitrag.