Natürlich hab ich (design as you go) den PAP noch ein paar mal radikal geändert und das Konzept einige Male wieder über den Haufen geschmissen. Aber jetzt läuft zumindest eine Rohfassung, und die möchte ich euch nicht vorenthalten. Was bei mir wie immer fehlt ist eine Foolproof Fehlerbehandlung, da müsste man noch einiges tun. So wie es ist kann man das Ding keinesfalls in einer echten, life WordPress Installation verwenden, das wäre selbstmörderisch. Aber auf meinem lokalen Webserver ist es gut aufgehoben und kann als Ausgangsmaterial für ein vernünftiges Plugin dienen.
Die wichtigsten Punkte in meinem umgearbeiteten PAP im Überblick:
- es gibt zwei Plugins. Eins erstellt die CSV-Datei mit den Stichworten aus den Titeln der Beiträge. Das zweite erzeugt eine Konfiguration für die Ausgabe (später mehr) und stellt einen Shortcode bereit, der das Stichwortverzeichnis an einer beliebigen Stelle (Seite) erzeugt.
- Die CSV-Datei findet auf wundersame Weise ihren Weg in das Verzeichnis des zweiten Plugins. Das Plugin liest die Datei zeilenweise in ein Array ein und erzeugt daraus ein hübsch alfabetisch sortiertes Stichwortregister. Klick auf ein Stichwort öffnet eine Unterseite und gibt als Parameter das aktuelle Stichwort mit.
- Damit eine Liste der gefundenen Beiträge zu einem Stichwort ausgegeben werden kann, ist die Ausgabe auf einer Unterseite zwingend notwendig. Dies ist eine ganz normale WordPress-Seite, die beim Anlegen der Plugin-Konfiguration neu erzeugt wird. Sie enthält nur einen Shortcode, der den beim Aufruf übergebenen Parameter stichwort übernimmt und daraus eine Liste der Beiträge zu diesem Stichwort erstellt. Die ID und der Permalink dieser Seite werden in der wp_options gespeichert. Diese Seite taucht auch ganz normal unter „Alle Seiten“ auf. Wenn man sie löscht – Pech. Da fehlt wieder die Fehlerbehandlung.
- Vorläufig gibt es keine Möglichkeit, die Konfiguration des zweiten Plugins nachträglich zu ändern. Für Entwickler: man kann die Einträge in der wp_options manuell löschen, dann kann man die Konfiguration neu schreiben. Das sollte man aber nicht im laufenden Betrieb tun, Pfusch auf der Datenbank kann zu Serverabstürzen führen. Hier To Do.
So, genug ge-PAP-t. Jetzt wollen wir uns mal das Plugin ShortcodeStichwort näher ansehen.
Teil 1 die Konfiguration
Ich erzeuge zunächst einen Eintrag im Admin-Menü, wie gehabt:
//********************* Eintrag im Adminmenü erzeugen
add_action('admin_menu', 'shortcodestichwort_plugin_setup_menu');
function shortcodestichwort_plugin_setup_menu(){
add_menu_page( 'ShortcodeStichwort', 'Shortcode Stichwort Konfiguration', 'manage_options', 'shortcodestichwort', 'shortcodestichwort_init' );
}
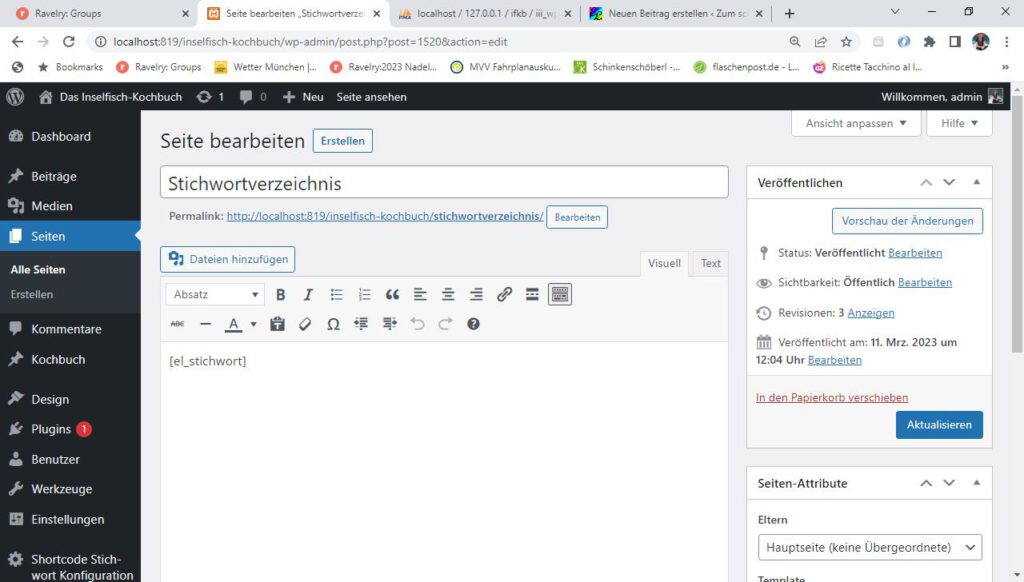
Dann gehts los: die Funktion shortcodestichwort_init fragt zuerst mal ab, ob eine Konfiguration bereits existiert, dazu hab ich einen Flag in der Options-Tabelle gesetzt:
function shortcodestichwort_init(){
echo "<h2>Konfiguration für die Ausgabe Stichwortverzeichnis</h2>";
//Prüfen, ob bereits eine Konfiguration gespeichert wurde
$checkkonfig = get_option('stichwortkonfigexists');
if ($checkkonfig == ""){
echo "Noch keine Konfiguration gespeichert. Sie müssen einmal auf den Button Konfiguration speichern klicken. ";}
Der Button „Konfiguration speichern“ wird nur angezeigt, wenn noch keine Konfiguration vorhanden ist. Gleich mehr.
Wenn bereits eine KOnfiguration vorhanden ist, wird sie ausgelesen und angezeigt:
if ($checkkonfig == 'existiert'){
echo "Konfiguration auslesen</br>";
echo "Konfiguration: ".get_option('stichwortkonfigexists')."</br>";
echo "Name der CSV-Datei: ".get_option('name_csvdatei')."</br>";
echo "URL der Ausgabeseite: ".get_option('url_ausgabeseite')."</br>";
echo "ID der Ausgabeseite: ".get_option('id_ausgabeseite')."</br>";
}
Das Formular wird nur angezeigt, wenn noch keine Konfiguration vorhanden ist (To Do)…
//***************Begin Formular
//Formular und Button nur anzeigen, wenn Konfiguration noch nicht existiert
if ($checkkonfig == ""){
//Formular mit Buttons
// Konfiguration speichern schreibt die Parameter in die wp_options
echo "<form action = '#' method = 'post'>";
echo "<input type='submit' id='el_button2' name='ButtonKonfig' value='Konfiguration speichern'>";
echo "</form>";
if (isset($_POST['ButtonKonfig'])){
return konfiguration_speichern();
}
//*****************End Formular
}
Die beim Klicken auf den Button aufgerufene Funktion konfiguration_speichern() macht Folgendes: Sie setzt den Flag stichwortkonfigexists und schreibt den Dateinamen der CSV-Datei in die wp_options. Dann wird die Ausgabeseite neu erstellt, sie kriegt gleich den Shortcode zur Erstellung der Linkliste mit. Dateiname und ID werden in der wp_options gespeichert.
function konfiguration_speichern(){
echo "Ich speichere die Konfiguration";
add_option('stichwortkonfigexists', 'existiert');
add_option('name_csvdatei','stichwortliste.csv');
//Hier wird die Ausgabeseite neu erstellt und gleich der Shortcode für die Unterseite mitgegeben
$my_post = array(
'post_title' => 'Ausgabeseite für das Stichwortverzeichnis',
'post_content' => '[links_ausgeben]',
'post_status' => 'publish',
'post_author' => 1,
'post_category' => array(1),
'post_type' => 'page'
);
// Insert the post into the database
//wp_insert_post( $my_post );
$seite_erzeugen = wp_insert_post( $my_post );
echo $seite_erzeugen;
echo get_permalink($seite_erzeugen);
$guid_seite = get_permalink($seite_erzeugen);
echo "Seite erzeugt";
//the_guid($my_post);
//Ende Ausgabeseite neu erstellen
//guid und ID in der Tabelle wp_options speichern
add_option('url_ausgabeseite', $guid_seite);
add_option ('id_ausgabeseite', $seite_erzeugen);
}
Das war Teil 1. Ich hol mir mal eine Tasse Tee, Kaffee hab ich heute schon genug gehabt 🙂
Teil 2: die Shortcodes
Ich muss meinen umgestrickten PAP nochmal korrigieren: ich erzeuge zwei Shortcodes. den ersten um das Stichwortregister anzuzeigen (Stichworte alfabetisch nach Buchstaben geordnet) und den zweiten um in der Unterseite die Linkliste anzuzeigen. Frisch ans Werk!
add_shortcode( 'el_stichwort', 'el_stichwort_handler_function' );
function el_stichwort_handler_function(){
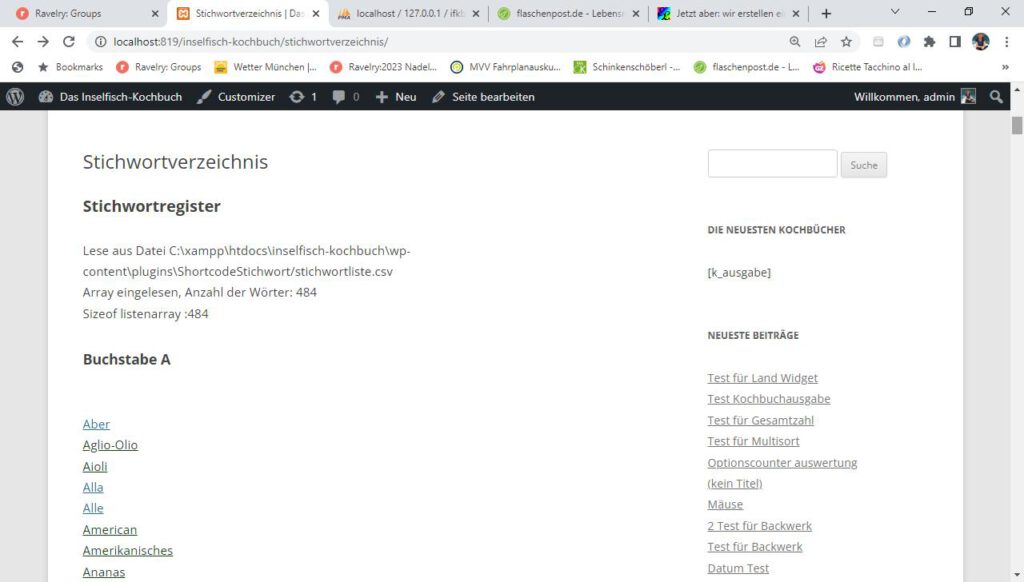
echo "<h2>Stichwortregister</h2>";
Jetzt wird die CSV-Datei zeilenweise eingelesen und auf ein Array gelegt. Die Funktion csv_einlesen schenke ich mir, das kann jeder selber komponieren. Hier ist noch eine Debug-Ausgabe mit der Größe des fertig eingelesenen Arrays drin.
//Variable für Liste bereitstellen
$listenarray = array();
//csv-Datei einlesen
$listenarray=csv_einlesen();
echo "Sizeof listenarray :".sizeof($listenarray)."<br>";
Jetzt wirds spannend: ich steppe durch das Alphabet und gebe zu jedem Buchstaben die zugehörigen Stichwörter aus. Jedes Stichwort wird als Link formatiert, der die Unterseite (aus der wp_options) mit dem Parameter stichwort aufruft.
//Array mit Alfabet erzeugen
$alphas = range('A', 'Z');
//Durch alfabet durchsteppen
foreach($alphas as $letter){
echo "<h3>Buchstabe ".$letter."</h3></br>";
//Nur einfügen, wenn mit dem richtigen Buchstaben anfängt
foreach($listenarray as $einwort)
{
$hilf = substr($einwort,0,1);
//***** Zeile mit a href und dem richtigen Pfad aufbauen ACHTUNG Absturzgefahr
if ($hilf == $letter){
//*****Ausgabeseite wert der Option holen und damit aufmachen
$pfad_unterseite = get_option('url_ausgabeseite');
//Link auf die Unterseite mit Übergabe des Stichworts als Parameter
echo '<a href="', "".$pfad_unterseite."?stichwort=$einwort",' ",">', $einwort, '</a></br>';
}
}
}//ende for each buchstabe
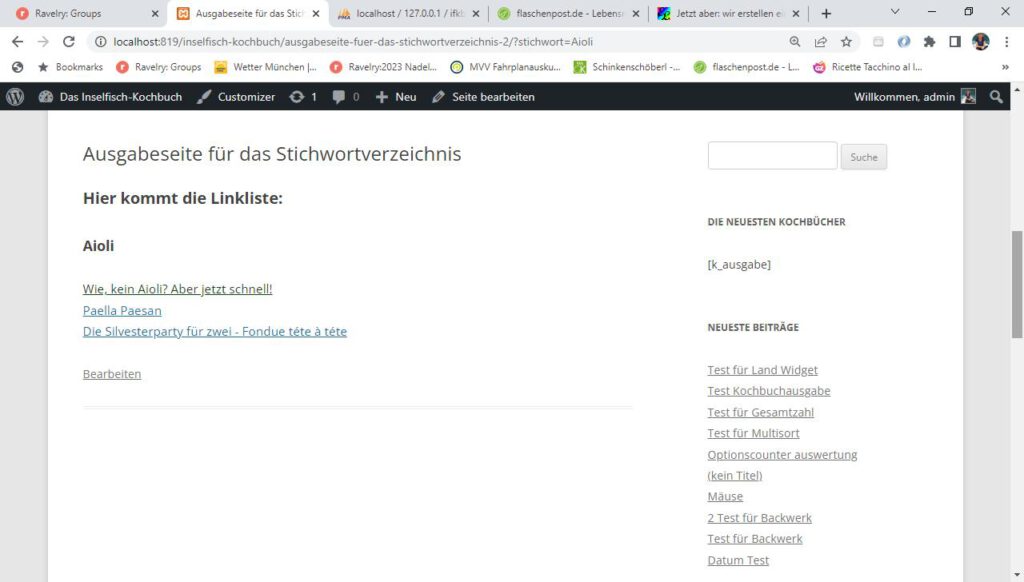
Schnieke Sache, nicht wahr? Fehlt nur noch der Code zur Erzeugung der Linkliste auf der Unterseite, den muss ich noch ein bisschen bereinigen, der Name der Tabelle Posts ist fest verdrahtet. Aber so funkt es. Ich gehe mit dem Stichwort zuerst ins Feld post_title und gebe die Treffer aus, dann gehe ich nochmal rein, in das Feld post_content (und nicht wie post_title) und gebe die ebenfalls aus. Thazzit!
//**********************Beginn Shortcode für die Ausgabe der Stichwortliste erzeugen To Do: Tabellenname iiiwpposts als Var generieren
add_shortcode( 'links_ausgeben', 'links_ausgeben_handler_function' );
function links_ausgeben_handler_function(){
echo "<h2>Hier kommt die Linkliste:</h2>";
$aktStichwort = $_GET['stichwort'];
//echo $aktStichwort;
echo "<h3>".$aktStichwort."</h3>";
$neu=$aktStichwort;
global $wpdb;
//erst treffer aus dem Titel rausfischen
$alleposts = $wpdb->get_results("SELECT DISTINCT(post_title), guid from iii_wpposts where post_title like '%$neu%' and post_status = 'publish' and post_type = 'post'");
foreach ( $alleposts as $einpost )
{
//echo $einpost->post_title, $einpost->guid."<br>";
echo '<a href="', $einpost->guid, '/",">', $einpost->post_title, '</a></br>';
}
//dann treffer aus dem content ohne treffer aus dem title rausfischen(dubletten vermeiden)
$alleposts = $wpdb->get_results("SELECT DISTINCT(post_title), guid from iii_wpposts where post_title not like '%$neu%' and post_content like '%$neu%' and post_status = 'publish' and post_type = 'post'");
foreach ( $alleposts as $einpost )
{
// echo $einpost->post_title, $einpost->guid."<br>";
echo '<a href="', $einpost->guid, '/",">', $einpost->post_title, '</a></br>';
}
}//**********************Ende Shortcode für die Ausgabe der Stichwortliste erzeugen
Jetzt fehlen noch ein paar Screenshots, aber dafür gibts einen neuen Beitrag.