Ich lieeebe einfache Lösungen! Da ich umständehalber meine Haushaltsausgaben besser überwachen möchte, hab ich mir eine wirklich simple Lösung einfallen lassen. Man braucht dazu ein Spreadsheet und eine Datenbank, ich bin dazu Windows-rückfällig geworden und arbeite mit Excel und meinem heißgeliebten alten Access.
Kleiner Meckerpott zwischendurch:
ich fahre ja eigentlich auf meinem Hauptrechner sehr zufrieden mit Linux, aber was ich beim Versuch mit Base (dem LibreOffice Datenbankprogramm) meine Auswertungen zu fahren erlebt habe, war grottenmäßig. Ich hab stundenlang an einem Datenimport ASCII oder auch Excel/Calc hingeastet und nichts hat funktioniert. Keine Umlaute, kein Währungsformat, Zahl beharrlich als Text importiert und nachträglich nicht zu ändern,statt Daten zu importieren werden sie in Calc geöffnet… nee Leute, Base hat mich nicht überzeugt. Ich hab mein Spreadsheet gepackt (als xlsx gespeichert) und bin auf meinen alten Windows-Laptop umgezogen. Ah, ich sags euch, herrlich! Ein Paradies für eine alte Statistikerin wie mich!
Nachtrag: ich leiste Abbitte, es geht doch, und zwar nach dieser Anleitung:
https://help.libreoffice.org/latest/de/text/shared/guide/data_im_export.html
Ist zwar nicht ganz fehlerfrei, so werden Zahlen- und Datumsfelder nicht automatisch erkannt, und das Währungsformat fehlt gänzlich, das ist nicht schön. Es geht mit einem Umweg über Calc und die Zwischenablage, dann kann man mit einem Assistenten ähnlich wie in Access arbeiten und die zu importierenden Felder manuell auswählen. OK, wollen wir mal nicht so kleinlich sein und die €-Beträge als Number mit 2 Dezimalstellen führen. Für die Diagramme in Calc gibts dann wieder €.
Fangen wir vorne an: Die Datenerfassung
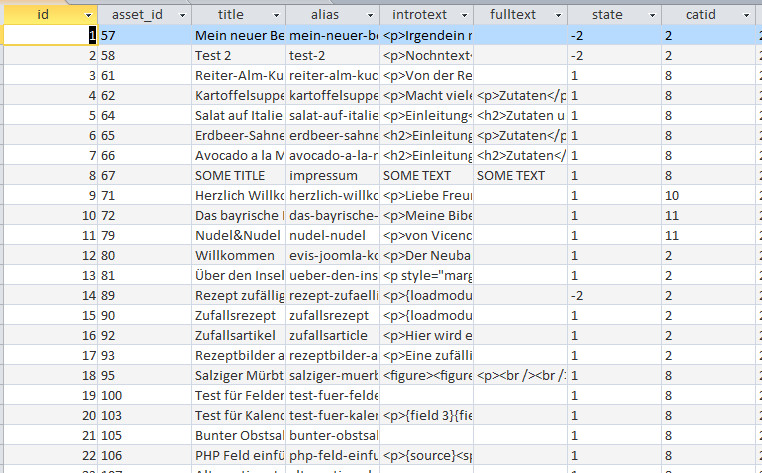
Aber ich schweife ab. Lasst uns ganz vorne abfangen. Die Grundlage jeder Statistik ist die Datenerfassung, da beißt die Maus kein Faden ab. Heißt in der Praxis: überall Kassenzettel mitgeben lassen und täglich eintippen. Manchen Läden bieten auch einen sog. e-Bon an (Kassenzettel elektronisch übermittelt) aber das hab ich noch nicht ausprobiert. Also reinhacken, und zwar in einer für die Auswertung sinnvollen Form. Dazu nimmt man gern eine Tabellenkalkulation wie Calc oder Excel, weil die angenehm zu bedienen sind. Meine Haushaltsbuch-Erfassungs-Tabelle sieht so aus:
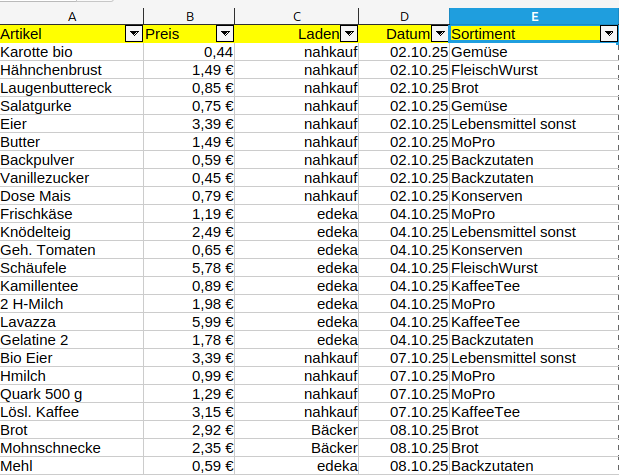
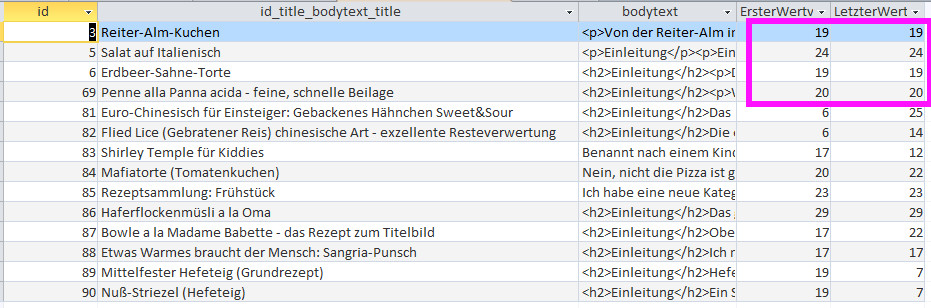
Das Flatfile
Ich höre schon den Aufschrei aller alten Datenbankler: das ist doch redundant und nicht normalisiert! Das, liebe Freunde der Statistik, ist ein klassisches Flatfile und hat mit Datenbankkonventionen erstmal nix zu tun. da steht halt -zig mal edeka oder Nahkauf, und auch im Sortiment und Datum gibt es vielfache Einträge und basta. ShiSho (shit in shit out) sagten meine amerikanischen Kollegen damals, wenn du die richtigen Daten nicht reingibst, kommt auch nur Mist raus. Das Sortiment ist übrigens biologisch gewachsen, das habe ich mir beim Eintippen der Reihe nach einfallen lassen. Man sollte es recht konsequent verwenden und nicht ständig neue Sortimentseinträge erfinden. Zum Tippen gehts einfach, weil das Spreadsheet eine Auto-Vervollständigen-Funktion hat und es reicht wenn man nur die Anfangsbuchstaben eintippt. Das Datum gibt man pro Kassenzettel nur einmal ein und ziehts dann mit Copy and Paste runter.Beim Artikel sollte man ein wenig Disziplin walten lassen und die Namen für gleiche Artikel gleich schreiben. Andererseits ist eine Auswertung auf Artikelbasis schon ziemlich esoterisch, das reicht mir wenn ichs im Flatfile sehen kann.
Also, wir haben folgende Felder:
| Artikel | Preis | Laden | Datum | Sortiment |
Dann tippen wir brav unsere Kassenzettel ein. Wenn man das gleich jeden Tag erledigt, ist es in ein paar Minuten fertig. Und eins ist wichtig: ehrlich sein, nix unterschlagen, auch nicht das Eis am Sonntagnachmittag oder den Kaffee und Kuchen in der Konditorei.
Kleine Erklärung zwischendurch
Sie vermissen die „grossen“ Ausgaben wir Miete, Strom, Heizung, Telefon etc? Die sehe ich auf meinem Kontoauszug, und ich kann sie beim besten Willen nicht ändern. Natürlich kann man versuchen Strom zu sparen und statt die Heizung anzudrehen einen warmen Pullover anzuziehen, aber wir wollens mal nicht übertreiben. Ein wichtiger Posten allerdings fehlt bei mir, weil ich kein Fahrzeug habe: die Benzinkosten. Die treiben in vielen Haushalten die Kosten in die Höhe, und man sollte schon ein Auge darauf haben.
Erfassung fertig – und erste Schritte im Spreadsheet
Es lohnt sich schon nach etwa zwei Wochen, eine erste Auswertung zu fahren. Als erstes setzt man mal eine Summe unter die Spalte mit dem Preis, das sind logo die gesamten Ausgaben.
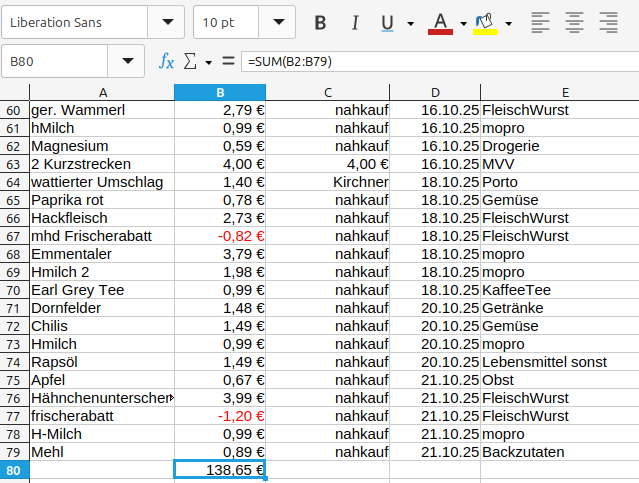
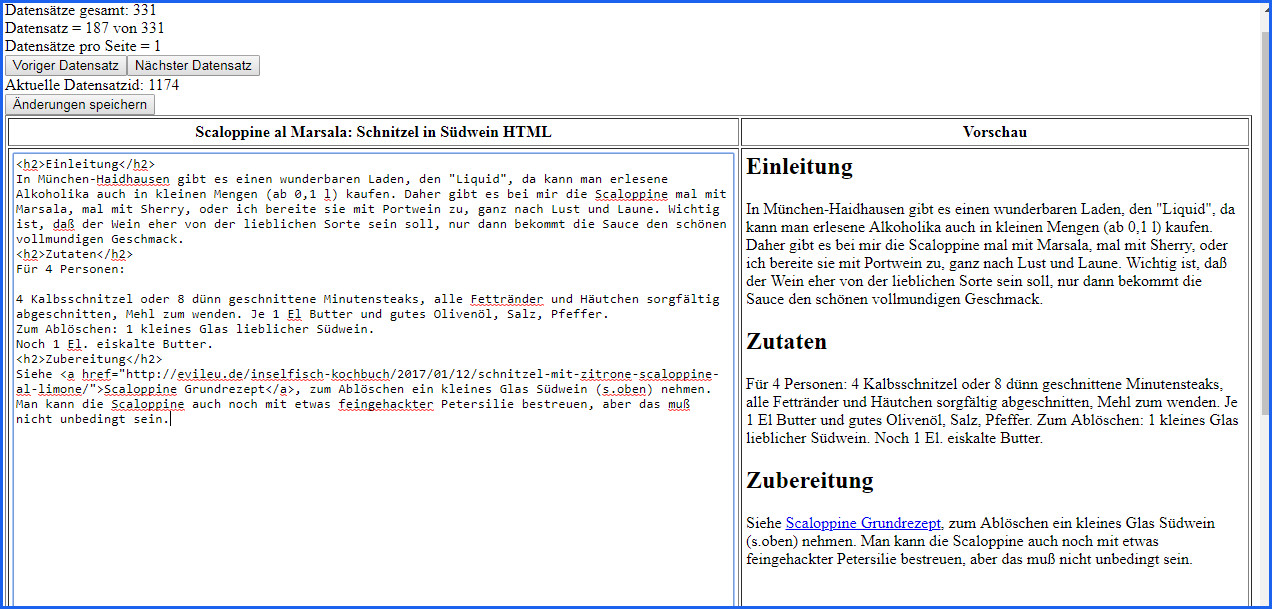
Nützliches Werkzeug: der AutoFilter
Dann spielt man ein bisschen mit einem Auto-Filter und schaut sich mal an, wieviel man in einem bestimmten Laden ausgegeben hat, und zum Beispiel noch was man alles für einzelne Sortimente gekauft that. Leider ließ sich mein Screenshot-Utility nicht dazu überreden, das Autofilter-Fenster aufzunehmen, aber es ist eigentlich selbsterklärend. Man kriegt z.B. eine Liste alle vorhandenen Läden angezeigt, und kann einen oder mehrere auswählen. Ich nehme mal nur den nahkauf: Und sehe sofort, dass ich da spätestens jeden zweiten Tag einkaufe.
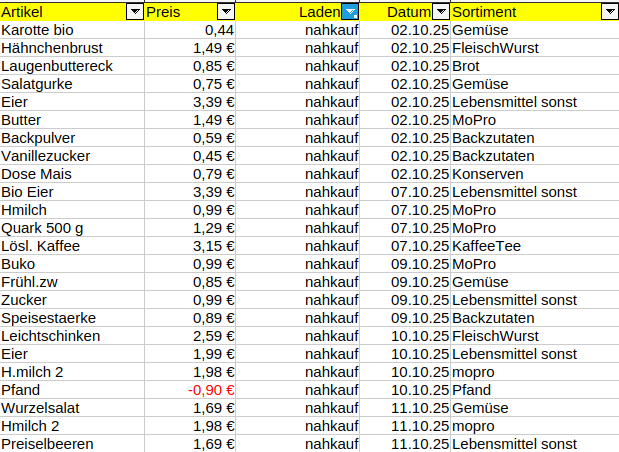
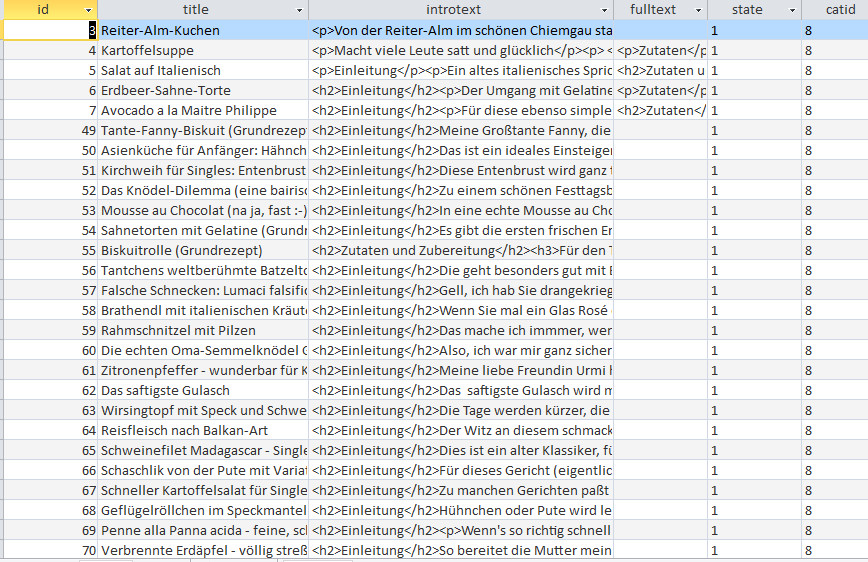
Oder ich schau mir mal an, was ich so an Fleisch und Wurst eingekauft habe:
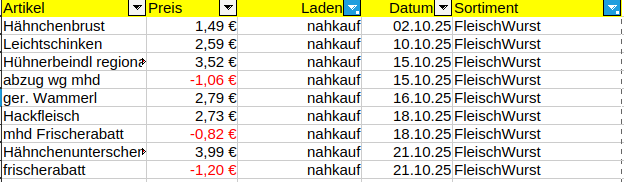
Mhm, das ist recht viel. Man sieht hier auch rote Zahlen, die werden vom EKPreis abgezogen, das ist der sogenannte Frischerabatt wenn das MHD naht und die Ware heruntergesetzt ist. Ich schlag da ganz gern zu, das ist ja noch einwandfrei, man muss es nur zeitnah verbrauchen.
Seht ihr wie der Hase läuft? Mit dem Flatfile im Spreadsheet kann man sich schon ein bisschen mit den Daten vetraut machen, ehe es ernst wird und die Datenbank zum Einsatz kommt. Nicht verbasteln, die grossen Auswertungen mit Summen und Gruppierungen machen wir in der Datenbank, da gehts viel einfacher als im Speadsheet! Finde ich jedenfalls.
Auf gehts zum Datenbanken
Wenn man mit Calc gearbeitet hat, speichert man die Datei als xlsx ab, mit Excel erübrigt sich das natürlich. Dann, täterätää, gehts los: Access aufmachen und eine neue leere Datenbank anlegen.
(Anmerkung am Rande: wenn jemand herausfindet, wie man das Flatfile korrekt nach Base importieren kann, bitte Bescheid sagen! Ich habs aufgegeben und bleib bei Access.)
Zuerst müssen wir unser Flatfile laden. Das geht folgendermassen:
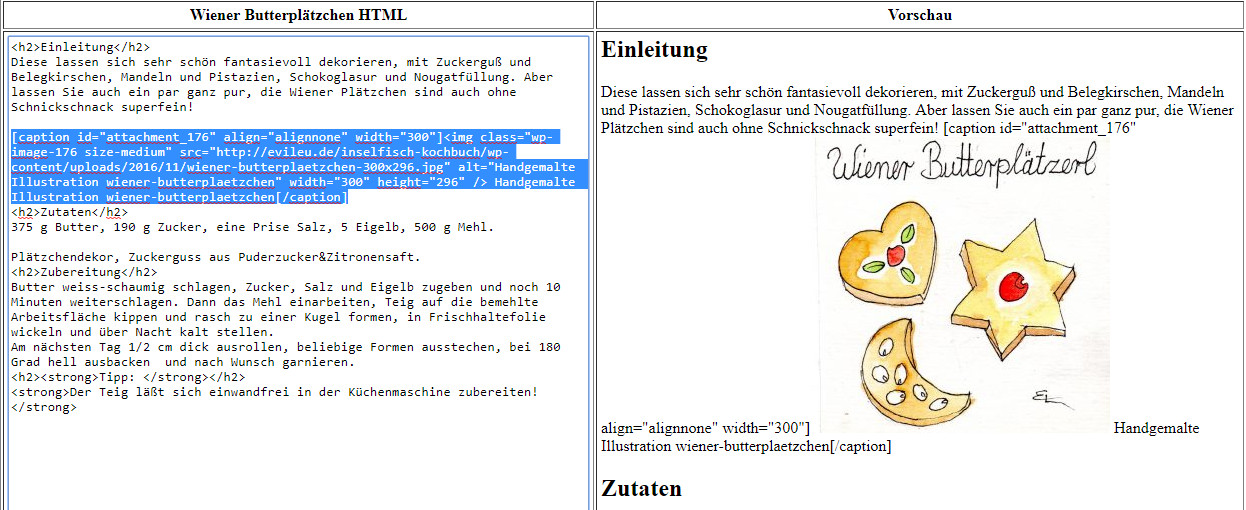
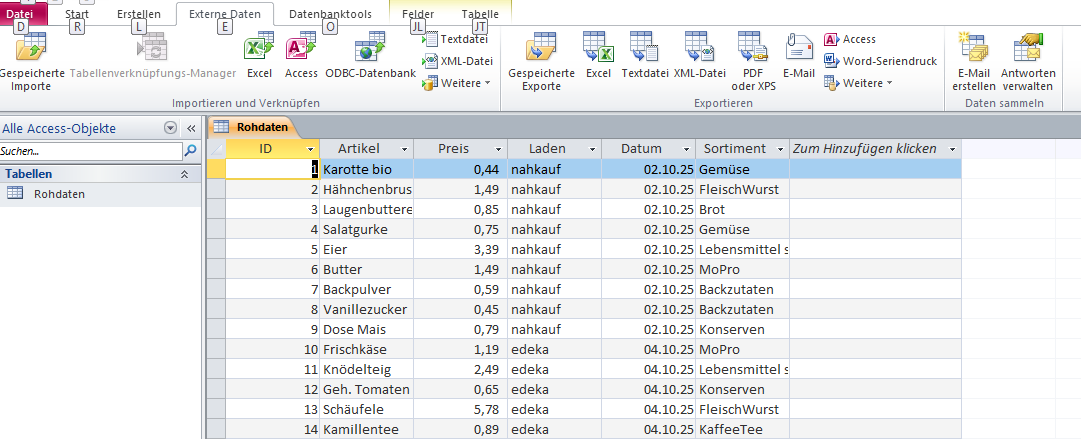
Unter externe Daten auf das Excel-Icon klicken, mit durchsuchen zum Excel-File navigieren, dden ersten Punkt „Importieren in eine neue Tabelle“ auswählen. Dann wird ein Auszug des ersten Arbeitsblattes angezeigt. Der Excel-Import in Access importiert immer nur ein ausgewähltes Arbeitsblatt, das ist eigentlich logisch, weil ja nur in eine einzelne Tabelle importiert wird. Man vergewissere sich, dass das richtige Arbeitsblatt angezeigt wird, und klickt auf Weiter- Erste Zeile enthält Spaltennamen auswählen, kurz drüberschauen ob alles paßt, weiter. Jetzt kommt ein eminent wichtiger Schritt, nämlich die Vergabe der richtigen Datentypen für die einzelnen Felder. Es ist eigentlich selbsterklärend:
Artikel Text, Preis Währung, Laden Text; Datum Datum/Uhrzeit, Sortiment Text. Und Schuss 🙂
Primärschlüssel soll von Access hinzugefügt werden, Weiter, Tabellenname vergeben, ich wähle „Rohdaten“, Fertig stellen. Wer möchte kann sich die Importschritte für die Zukunft speichern.
Ich öffne die Tabelle, und Halleluja, es kann losgehen!
Die erste Abfrage: wofür gebe ich mein Haushaltsgeld eigentlich aus?
Dafür werten wir den Preis pro Sortiment aus, da kommt dann raus was ich für Fleisch, Molkereiprodukte, Porto usw. tatsächlich ausgegeben habe. Ich mach sowas gern im Assistenten, die ganz harten Freaks tippen das SQL ein. Aber schön der Reihe nach, damit auch jeder mitkommt.
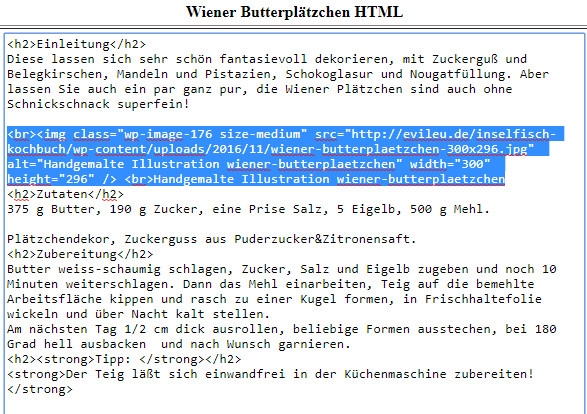
Das ist jetzt echt Access für blutige Anfänger, aber einmal exerzieren wir es durch, damit sich auch Leute zurechtfinden die noch nicht viel mit Access und Datenbanken überhaupt gearbeitet haben. Wir rufen den Abfrage-Assistenten auf, der steckt unter Erstellen/Abfrage-Assistent Icon, und wählen Auswahlabfrage-Assistent. Als zugrundeliegende Tabellen müsste eigentlich unsere Rohdaten drinstehen, wir haben ja nur die eine Tabelle. Wir wählen die Felder Preis und Sortiment, und weiter. Detail sollte angewählt sein, weiter. Abfrageentwurf anwählen, fertig stellen. Das sieht so aus:
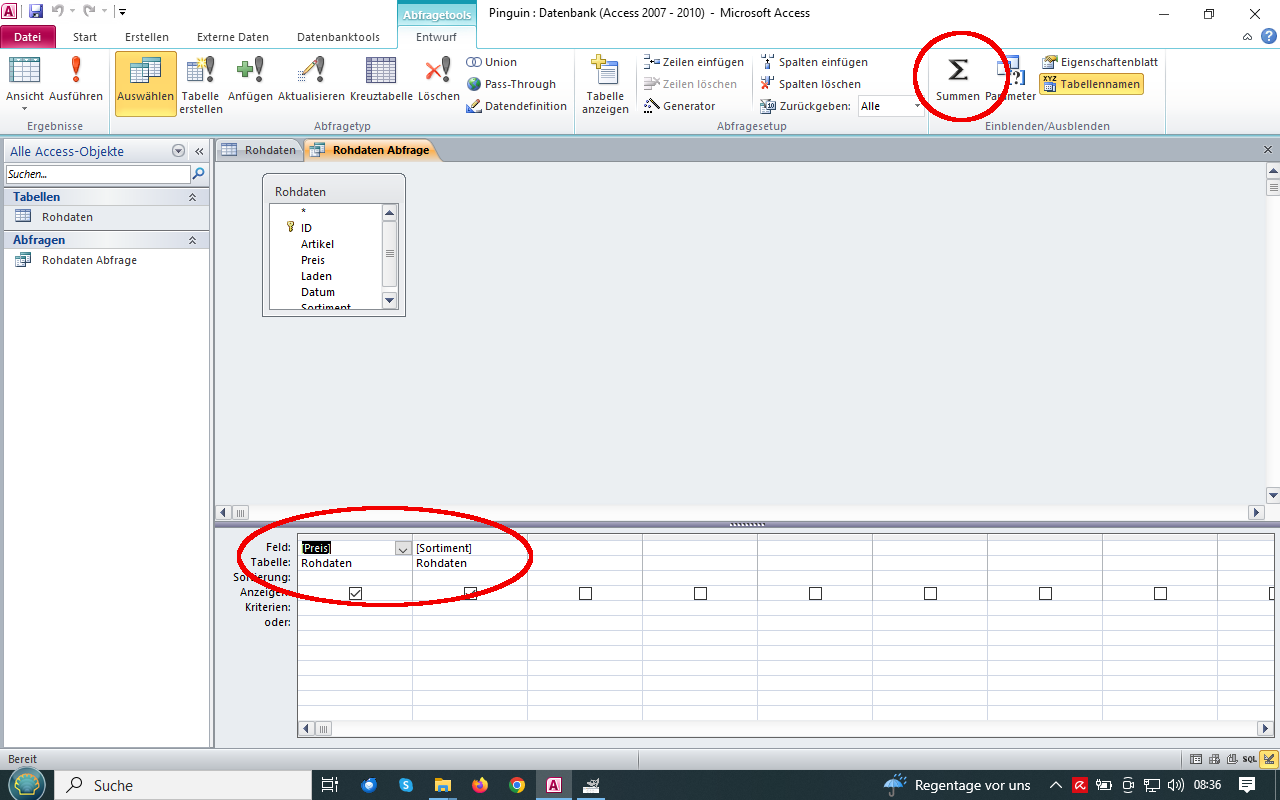
Unten sind unsere gewählten Felder eingeblendet. Eminent wichtig ist oben in der Menüleiste das Summenzeichen, damit blenden wir nämlich die Aggregatfunktionen ein, die wir für diese Auswertung brauchen. Der Preis wird summiert und absteigend sortiert, das Sortiment wird gruppiert, so soll es aussehen:
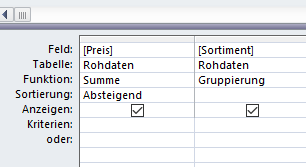
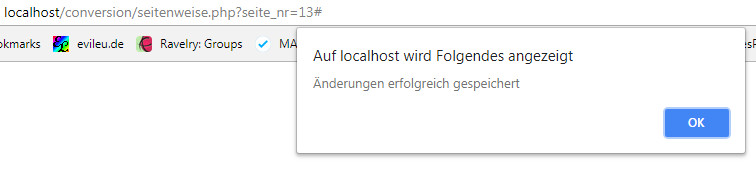
Wenn wir jetzt die Abfrage ausführen, erhalten wir folgendes prächtige Ergebnis:
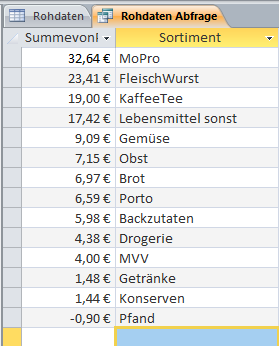
Na bitte, juckt es sie da nicht in allen Excel-oder Calc-Fingern, das schreit doch nach einem Diagramm-Törtchen! Calc möchte übrigens die Daten genau andersherum, also in der ersten Spalte die Beschriftung, in der zweiten Spalte die Summe von Preis. Sonst wirds kompliziert…
Ich hab wieder Linux zum Zug kommen lassen und machs mit Calc.
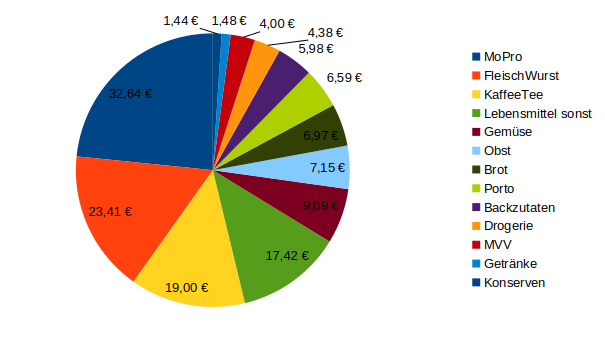
Na, das war doch jetzt gar nicht schlimm, oder? Für Perfektionisten liefere ich noch das SQL der Abfrage nach:
SELECT Sum(Rohdaten.[Preis]) AS SummevonPreis, Rohdaten.[Sortiment]
FROM Rohdaten
GROUP BY Rohdaten.[Sortiment]
ORDER BY Sum(Rohdaten.[Preis]) DESC;
Weitere interessante Abfragen
Ich machs mir leicht und zeige hier nur das SQL, im Assistenten kanns sichs jeder selber zusammenpfriemeln. Da wäre als nächstes interessant, wieviel Geld ich in welchen Laden getragen habe, also die Summe über den Preis gruppiert nach Laden… hach ich liebe SQL, das ist doch sehr gut verständlich und einleuchtend:
SELECT Sum(Rohdaten.[Preis]) AS SummevonPreis, Rohdaten.[Laden]
FROM Rohdaten
GROUP BY Rohdaten.[Laden]
ORDER BY Sum(Rohdaten.[Preis]) DESC;
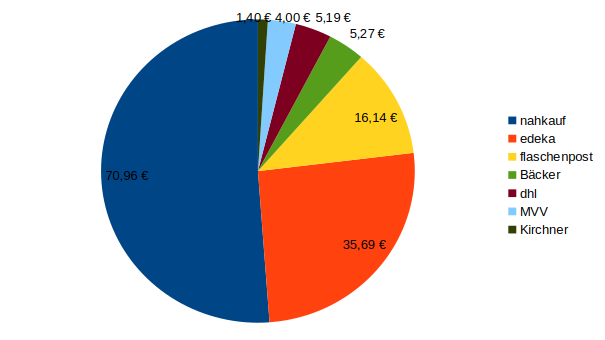
Als letztes machen wir noch die Ausgaben pro Tag, für die ist ein Balkendiagramm sinnvoll. Erst das SQL:
SELECT Sum(Rohdaten.Preis) AS SummevonPreis, Rohdaten.Datum
FROM Rohdaten
GROUP BY Rohdaten.Datum
ORDER BY Rohdaten.Datum;
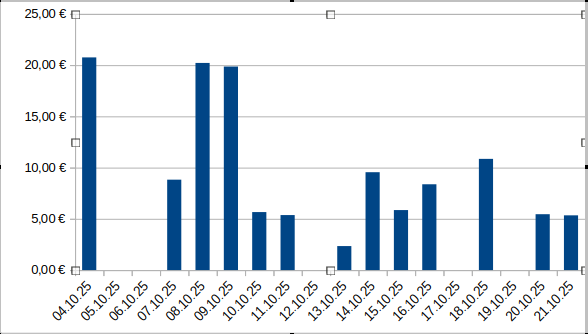
Na, das ist doch mal aussagekräftig… jetzt kann man hingehen und in den Rohdaten nachschauen, was bei den Spitzenwerten an einem bestimmten Tag ausgegeben wurde, aber damit lasse ich euch jetzt alleine, da kann jeder selber spielen. Mir jedenfalls hat es Spaß gemacht, und ich liebe es, mein Haushaltsbuch auszuwerten. Da macht sogar das Kassenzettel erfassen Spaß!