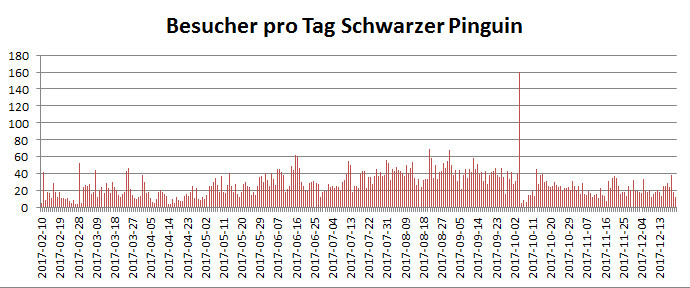
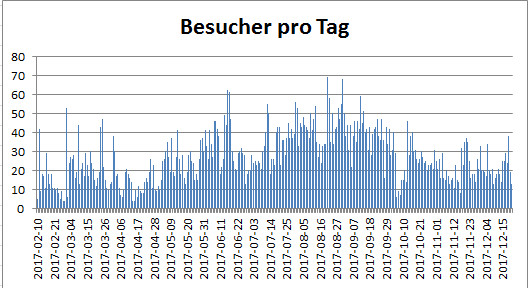
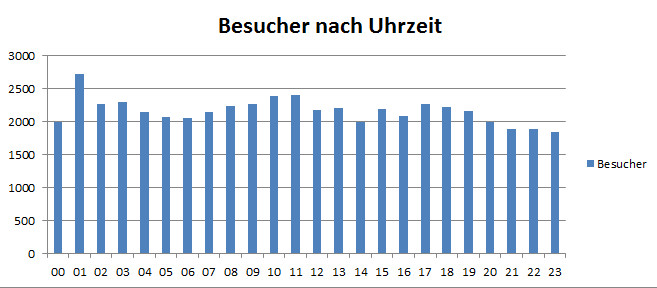
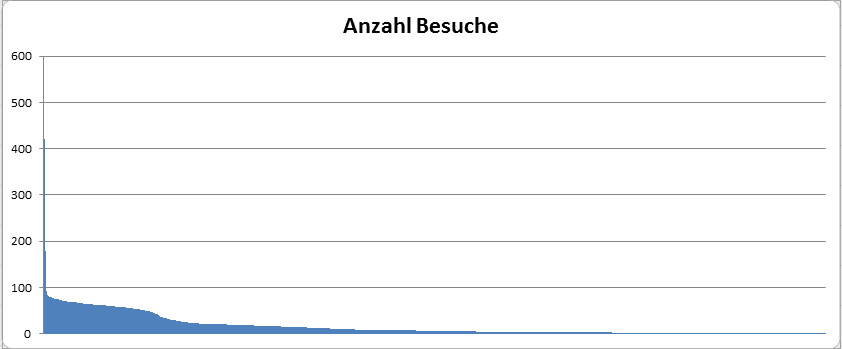
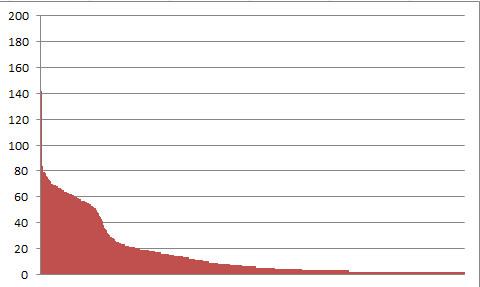
An diesem Wochenende hat mein Besucherzähler auf dieser Seite die 5.000er-Marke geknackt, und das ist eine respektable Zahl für einen sehr spezialisierten kleinen Blog wie den schwarzen Pinguin. Gezählt wird hier seit Februar diesen Jahres (2017), also hab ich hier rund gerechnet 5.000 Besucher in einem halben Jahr gehabt. Das freut mich persönlich sehr und ermutigt mich, mit meiner lockeren Plauderei über IT am Feierabend und WordPress im Speziellen weiterzumachen. Mir geht auch so schnell der Stoff nicht aus, keine Bange, nächste Woche gibts dann wieder Spaß auf der Datenbank!
Barrierefreiheit als SEO-Booster
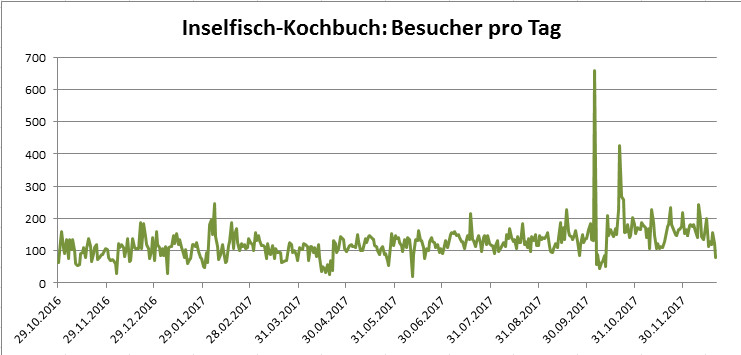
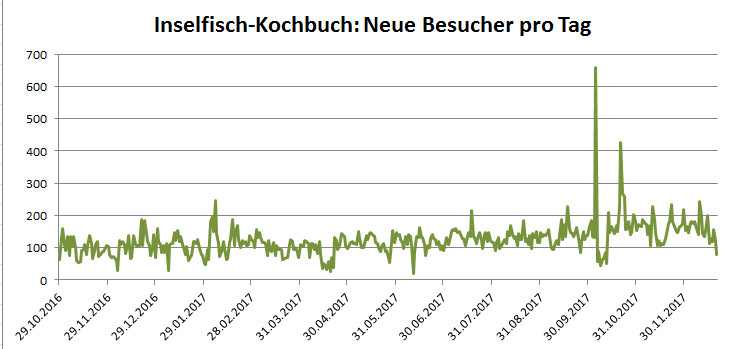
Da wir gerade beim Thema sind: der Renner auf evileu.de ist nach wie vor das Inselfisch-Kochbuch mit aktuell 33.648 Besuchern, und da sind die Besucherzahlen nach einem eh schon guten Start nochmal kräftig in die Höhe gegangen, seit ich das Kochbuch in Sachen Barrierefreiheit komplett umgebaut habe. Auch nicht schlecht läuft meine Oddballs-Handarbeitsseite, hier sind es immerhin auch schon 11.297 Besucher in einem halben Jahr. Das ist wirklich nicht übel für eine rein private Webseite, und ich werde oft gefragt, wie ich das denn gemacht habe.
Meine SEO-Tricks
Da muß ich euch leider enttäuschen. Ich nutze kein SEO-all-in-one Pack, ich jongliere nicht mit Keywords, mir ist mein Google Ranking egal, ich schalte keine Werbung, ich mach das hier alles zu Fuß.
Was ich allerdings schon mache: ich blogge wie der Weltmeister. Im Inselfisch-Kochbuch gibts mindestens einmal die Woche ein neues Rezept, hier quassel ich auch ungefähr ebenso oft aus dem Nähkästchen der alten Programmiererin, und auf den Handarbeitsseiten gibts regelmäßig Fotos meiner aktuellen Socken, Schals und Pullover und gelegentlich auch mal eine neue Anleitung zum Download als PDF. Das heißt, auf meinen Blogseiten ist regelmäßig Neues geboten, und das lieben nicht nur die Suchmaschinen, das lieben anscheinend auch menschliche Besucher.
Beiträge mit Hand und Fuß
Und ich erzähle halt nicht nur irgendeinen Keyword-gespickten Quark, meine Beiträge haben (meistens) Hand und Fuß. Nach meinen Kochrezepten kann auch ein Anfänger kochen, wenn man einen Schal nach meiner Handarbeitsanleitung strickt, dann wird das auch was, und wenn man meinen Code hier nachprogrammiert, dann funzt das auch. Das ist mein ganzes Geheimnis.
Wiederholungstäter und Mundpropaganda
Das sind meine wichtigsten Werbemittel. Meine streng wissenschaftlichen Analysen (ich hab einfach viele Leute gefragt) haben ergeben, dass gerade das Inselfisch-Kochbuch durch Mundpropaganda immer mehr Besucher bekommt, besonders das mit der Barrierefreiheit spricht sich hübsch herum. Und dann kommen meine Besucher auch wieder, sie benutzen das Kochbuch als Nachschlagewerk. Ich hab jetzt schon von vielen weiblichen Fans gehört, dass sie im Supermarkt mit dem Smartphone schnell mal ein Rezept im Inselfisch-Kochbuch nachschlagen und schauen, was sie dafür einkaufen müssen. Da hilft es natürlich, dass ein sauber umgesetztes WordPress-Theme im Regelfall fully responsive ist und auch auf dem Smartphone vernünftig dargestellt wird.
Spezialisierung: ein Blog, ein Thema
Das mit der Spezialisierung war bei mir dringend notwendig, weil ich so breitgefächerte Interessen habe. Ich male, ich programmiere, ich koche für mein Leben gern, ich schreibe Bücher für Kinder und für Erwachsene und produziere Handarbeiten am laufenden Band, und das ist noch lang nicht alles.
Ich habe in früheren Jahren schon mehrere vergebliche Anläufe gemacht, alle meine Interessensgebiete auf einer einzigen Webseite unterzubringen, und bin jedesmal an dieser Sysiphosarbeit gescheitert. Letztendlich war Wordpress der Schlüssel für die erfolgreiche Realisierung des Gemischtwarenladens evileu.de.
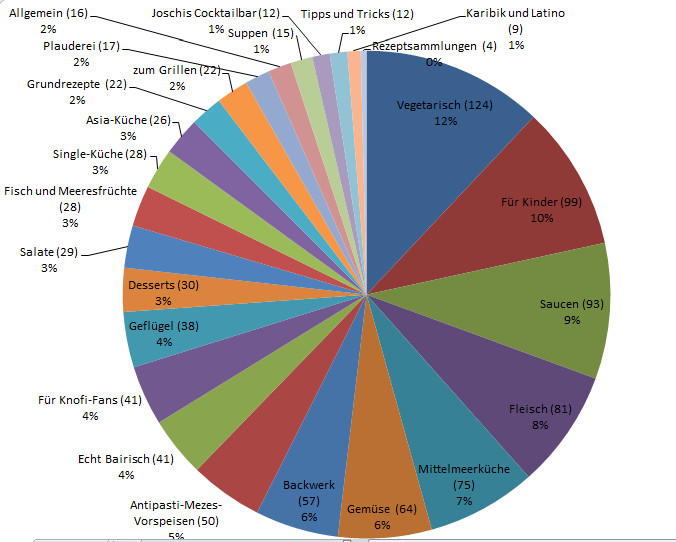
Ich habe jedem meiner vielen Hobbies einen eigenen Blog gegönnt, in dem ich jeweils nur über ein einziges Thema blogge. Es sind jetzt insgesamt etwas mehr als 10 Blogs, nicht alle sehr aktiv, aber doch eine stolze Anzahl für eine private Homepage. Wenn man nur mal auf die Seiten über meine Malerei schaut, das Thema ist jetzt aufgesplittet in meine Biographie als Malerin, meine Aquarelle, die Serie mit den blauen Planeten und dazu noch die Computergrafiken mit GIMP. Das macht 4 Kunst-Blogs, und die sind alle proppevoll mit Bildern und meinen Texten dazu. Aber eben sauber nach Themen getrennt, sonst verzettelt man sich. Und auch die Besucher verzetteln sich wenn eine Webseite zu viele verschiedene Topics anbietet, da werden die Menüs und Untermenüs und Unter-Untermenüs so verschachtelt, dass kein Schwein mehr durchblickt, und die Besucher nicht wiederkommen, weil sie nichts wiederfinden.
Jetzt fahre ich da eine ganz klare Linie, und das hat für mich als viel-Bloggerin den Vorteil, dass ich sofort weiß wohin damit, wenn mir eine Idee zu einem neuen Beitrag kommt. Und meine Besucher kennen sich auch aus, da jeder Themenblog einen unverwechselbarenb Look&Feel hat, und man sofort weiß ob man auf der Handarbeitsseite oder im Inselfisch-Kochbuch gelandet ist. Ich bin ein Buchhalterkind, ich liebe strukturierte Ablagesysteme!
Damit sind wir ganz wunderbar beim nächsten Stichwort gelandet:
Strukturierung: h1, h2 und Co.: eigentlich HTML für Anfänger
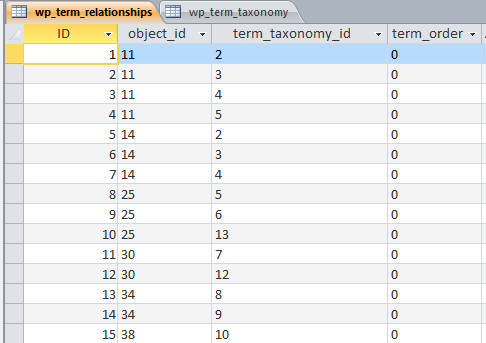
Ob sie es glauben oder nicht, Textverarbeitung am Computer gab es schon lange vor Windows und WYSIWYG. Ich erinnere nur an TeX/LaTeX oder an Word für DOS, wo man mitnichten auf dem Bildschirm angezeigt bekam, was dann auf dem Drucker herauskam. Damals lernten wir alles über die Verwendung von sog. Textauszeichnungen, in Word für Windows heißen sie Formatvorlagen. Und da HTML nichts anderes als eine Textauszeichnungssprache ist, gibt es sie hier genauso. Jeder kennt sie, kaum jemand wendet sie richtig an. Für Überschriften sind h1..h6 vorgesehen, eine Tabelle formatiert man mit Hilfe des <table>-Tags, es gibt nummerierte Listen, es gibt Image-Tags für die Bilder… das sind viele, aber doch nicht endlos viele. Eine hübsche komplette Liste aller HTML5-Tags findet ihr hier bei MDN Web Docs
Trennung von Text und Formatierung
Die Idee dabei ist, Text und Formatierung sauber zu trennen. Ein einfaches Beispiel: eine Hauptüberschrift soll fett, in Arial und in 30 Punkt Größe angezeigt werden. Was macht der WYSIWYG-Anwender? Er markiert den betreffenden Textabschnitt, drückt auf das Icon für „fett“, wählt in der Dropdownliste für die Schriftart „Arial“ und scrollt in der Schriftgrößen-Zahleneingabe rauf bis 30. Das erzielt zwar den gewünschten Effekt, aber es ist textverarbeitungstechnisch nicht sauber. Wie gehts richtig? Die Überschrift kriegt die Tags <h1>…</h1>, und wenn man es nicht dem Browser überlassen will wie eine Überschrift erster Ordnung dargestellt wird, legt man es in seiner CSS-Datei fest. Hierhin kommen unsere Textattribute, wenn man es richtig machen will.
Saubere Gliederung
Das habe ich bei der Umarbeitung meiner Webseiten auf barrierefrei neu lernen müssen, bei mir hatte sich da über die Jahre auch eine gewisse Schlamperei eingeschlichen. Ich schreibe ja sehr viel Text, und lange Textwüsten auf einer Webseite sind absolutes Bildschirmgift, die liest kein Schwein. Also, umdenken, Text in kürzere logische Einheiten unterteilen, Zwischenüberschriften einfügen, wo es Sinn macht, Listen und Tabellen verwenden. Das erhöht die Lesbarkeit und hält den Besucher bei der Stange, weil er nicht von unstrukturierten Endlostexten gelangweilt wird.
Einfaches Beispiel: Rezepte mit Struktur
Ich hätte da wieder ein einfaches Beispiel: alle meine Rezepte im Inselfisch-Kochbuch haben die selbe logische Gliederung:
- Einleitung
- Zutaten
- Zubereitung
- Tipps
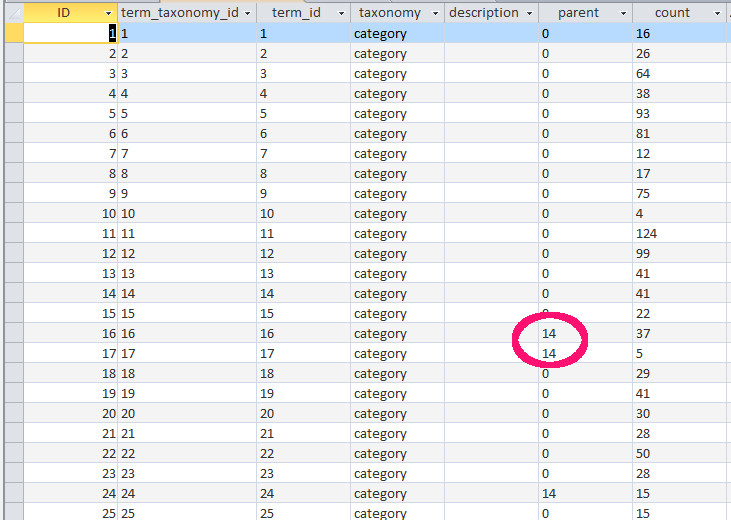
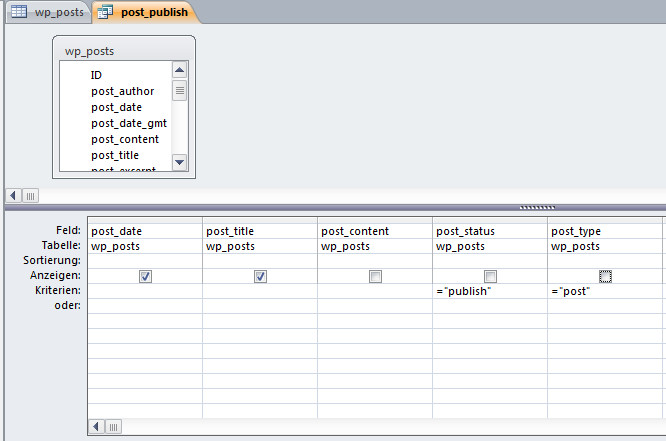
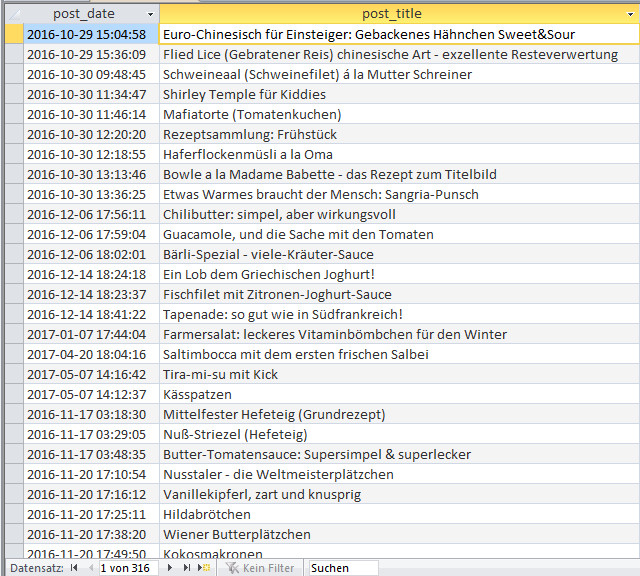
Diese Elemente sind als h2-Überschriften formatiert. H1 ist der Titel des jeweiligen Rezepts, das ist unser post_title aus WordPress. Der Text dazwischen ist einfach <p> wie Absatz. That’s all, nach diesem Muster schreibe ich alle meine Rezepte. Ich muß nicht drüber nachdenken wie ich es mache, und es hat bei meinem Publikum einen hohen Wiedererkennungswert und dient der allgemeinen Übersichtlichkeit und Verständlichkeit. Mehr ist nicht dran an der Strukturierung – machen muß man es halt!
Übrigens: Suchmaschinen lieben klar strukturierte HTML-Dokumente. Benutzer mit Handicap (Screenreader & Co.) lieben sie auch, weil sie so klar durch das Dokument navigieren können. Deswegen ist eine gute Textstrukturierung auch eine der wichtigsten Voraussetzungen der Barrierefreiheit nach WCAG.
Mehr ist nicht dran an meinem SEO-Programm
Mit dieser Strategie bin ich zu meinen stolzen Besucherzahlen gekommen, über alle Blogs gerechnet sind das jetzt insgesamt fast 50.000 seit Anfang des Jahres. Genug aus dem Nähkästchen geplaudert, ich mach hier mal die Kiste zu. Ich hab mir nämlich gerade ein neues Projekt in Sachen Barrierefreiheit angelacht, da hat der schwarze Pinguin jetzt ein bißchen Sendepause. Bis die Tage!