Da ich die ganze Mechanik schon mal programmiert habe, in Access mit Visual Basic, hab ich mir relativ leicht getan es auch in PHP zu lösen. Was gar nicht schön war: bei komplexeren Datenbankoperationen ist mir x-mal der Webserver abgeraucht. Deswegen hab ich dann die Notbremse gezogen und bin auf eine CSV-Datei ausgewichen. Nicht die schlechteste Lösung, was Stabilität und Performance angeht.
Was hab ich gemacht? Ich geh da mal im Schnelldurchlauf durch, haben wir alles schon mal so oder in ähnlicher Form gehabt. Trotzdem, das eine oder andere ist vielleicht gut zu wissen.
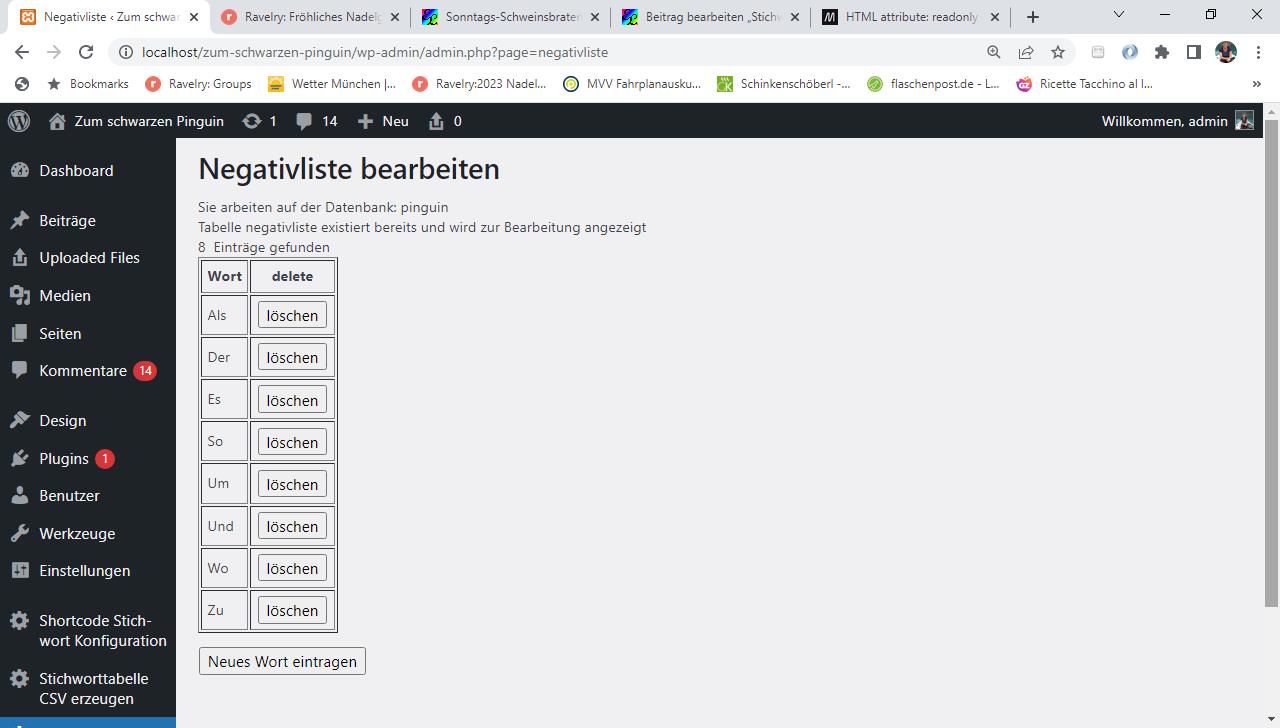
Also,, zunächst wird ein Plugin mit einem Eintrag für das Admin-Menü erstellt. Dazu legt man eine Datei an, die folgendermassen aussieht:
/*
Plugin Name: Stichworttabelle
Description: Erzeugt eine neue Stichworttabelle aus den Titeln der Beiträge (post_title)
Author: Evi Leu
Version: 0.1
*/
add_action('admin_menu', 'stichworttabelle_plugin_setup_menu');
function stichworttabelle_plugin_setup_menu(){
add_menu_page( 'Stichworttabelle', 'Stichworttabelle Plugin', 'manage_options', 'stichworttabelle', 'stichworttabelle_init' );
}
function stichworttabelle_init(){... HIER GEHTS MIT DER MAIN FUNCTION LOS
Diese Datei kommt in ein eigenes Unterverzeichnis „Stichworttabelle“ im Plugin-Verzeichnis deiner WP-Installation und heißt Stichworttabelle.php. Sie kann jetzt in der Liste der installierten Plugins aktiviert werden. Sie tut zunächst mal nichts ausser einen Eintrag im Admin-Menü zu erzeugen, der heißt „Stichworttabelle Plugin“ und ist erstmal noch eine leere Seite.
Die Menüseite wird in der Funktion function stichworttabelle_init() mit Leben gefüllt, erst kommt ein bisschen Infotex, dann wird der Name der Datenbank ermittelt und ausgegeben:
echo "<h1>Stichworttabelle neu erstellen</h1>";
echo "Das Plugin hat zwei Funktionalitäten: </br></br>
1. Diesen Admin-Menüpunkt Stichworttabelle Plugin, in dem die Stichworttabelle neu aufgebaut werden kann.</br>
Aus Performancegründe und wegen der Runtime-Stabilität wurde die Stichwortbasis in eine externe CSV-Datei ausgelagert. Diese wird neu erstellt, falls sie nicht schon vorhanden ist. Falls sie schon vorhanden sein sollte, wird sie überschrieben. Man kann die Datei beliebig oft neu erzeugen, z.B. wenn es grössere Mengen neuer Beiträge gibt.</br></br>
2. einen Shortcode [stichwortverzeichnis]. der an beliebiger Stelle in einem Beitrag oder einer Seite eingesetzt werden kann und dort ein Stichwortverzeichnis erzeugt.</br></br>";
global $wpdb;
//Datenbankname ermitteln
$mydatabase=$wpdb->dbname;
echo "Sie arbeiten auf der Datenbank: ".$mydatabase."</br>";
echo "Stichworte werden aus den Titeln ihrer Beiträge erzeugt</br>";
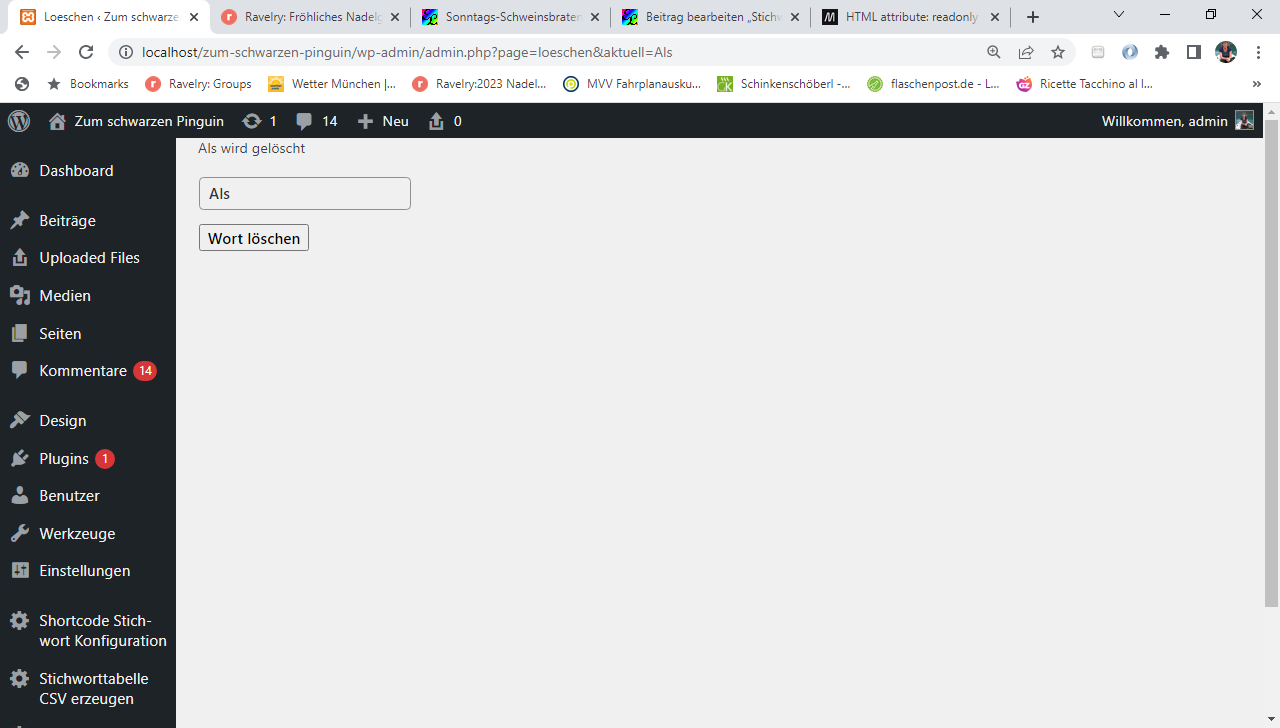
Dann kommt ein kleines Formular, das aus genau einem Button besteht:
//***************Begin Formular
//Formular mit Button
//"
// Stichwortliste Datei neu erzeugen startet die array-Erzeugung fuellen und befüllt die Datei stichwortliste.csv wieder
echo "<form action = '#' method = 'post'>";
echo "<input type='submit' id='el_button2' name='ButtonFuellen' value='Stichwortliste Datei neu erzeugen'>";
echo "</form>";
if (isset($_POST['ButtonFuellen'])){
return tabelle_fuellen();
}
//*****************End Formular
Wenn auf den Knopf gedrückt wird, wird die Funktion tabelle_fuellen aufgerufen. Jetzt wirds interessant:
function tabelle_fuellen(){
$neuesArray=array_erzeugen();
erzeuge_csv($neuesArray);
}
Die Variable $neuesArray wird mit Hilfe der Funktion array_erzeugen() befüllt. Diese erstellt eine Stichwortliste aus den Titeln aller Beiträge in der Tabelle wp_posts, dazu gleich mehr.
Dann wird die Funktion erzeuge_csv aufgerufen, sie kriegt als Parameter unser Array mit und schreibt die Einträge zeilenweise in eine Datei.
Frischauf, wir sehen uns die Funktion array_erzeugen() mal näher an. Der erste Teil mit den nötigen MySQL-Abfragen sieht so aus:
global $wpdb;
//Beginn Originalcode
$table_name = $wpdb->prefix.'posts';
//Datensätze zählen & Ausgabe Anzahl
$count_query = "select count(*) from $table_name where post_status='publish' and post_type = 'post'";
$num = $wpdb->get_var($count_query);
echo $num."  Beiträge gefunden</br>";
//******************
//Alle Datensätze vom Typ post und published ausgeben
$alleposts = $wpdb->get_results( "SELECT * FROM ".$table_name."
where post_status='publish' and post_type = 'post' order by post_title");
Das übliche Spiel wenn man die veröffentlichten Beiträge ausgeben will, man braucht in der Where-Klausel die Bedingung post_status=’publish‘ and post_type = ‚post‘. Und zugegeben, man könnte statt select * auch select post_title verwenden, das fällt mir erst jetzt auf.
Jetzt stecken alle veröffentlichten Beiträge als Array in der Variablen $alleposts. Durch dieses Array steppe ich jetzt mit foreach durch und nehme mir die einzelnen Einträge vor, die werden mit Hilfe der Funktion explode() am Leerzeichen gesplittet, mit preg_replace() von Sonderzeichen bereinigt und mit ctype_upper auf Groß/Kleinschreibung überprüft, ich nehme nur die groß geschriebenen Einträge. Das ist willkürlich festgelegt, produziert aber eine sehr brauchbare Stichwortliste. Schließlich wird der gefundene Eintrag mit array_push() in die Variable $stichwortliste weggeschrieben.
$stichwortliste = array();
//Durch alle gefundenen Datensätze durchsteppen
$zaehler = 0;
foreach ( $alleposts as $einpost )
{
//ersten gefundenen Titel in array aufsplitten
$liste = explode(" ", $einpost->post_title);
//Durch das Array durchsteppen
foreach ($liste as $einwort)
{
//Prüfen, ob Wort groß geschrieben ist
$wortanfang = substr($einwort,0,1);
//Sonderzeichen entfernen (nach Bedarf editieren)
$einwort = preg_replace('/[0-9\@\.\;\" "\(\)\:\?\!\,]+/', '', $einwort);
//nur ausgeben wenn Groß geschrieben
if (ctype_upper($wortanfang)){
$zaehler = $zaehler+1;
//Hier kommt der Knackpunkt: Neues Stichwort in Array schreiben
//***********************************
array_push($stichwortliste, $einwort);
//***********************************
}// ende von ctype_upper
}// ende von liste as einwort
}//ende von alleposts as einpost und array befüllen
Es folgt noch ein bisschen Kosmetik, und ganz am Ende gibt unsere Funktion das gebrauchsfertige Array zurück:
//Dubletten entfernen
$stichwortliste= array_unique($stichwortliste);
//Array sortieren
sort($stichwortliste);
//Ausgabe Anzahlen erzeugter Stichwörter
echo "Anzahl Stichwörter in den Rohdaten: ".$zaehler."</br>";
echo "Grösse des sortierten und Dubletten-bereinigten Arrays: ".count($stichwortliste)."</br>";
echo "<h2>Erzeuge neue Stichwortliste aus der Tabelle: ".$table_name."</h2>";
return $stichwortliste;
}// ende array erzeugen_function
Noch alle mit mir beieinander? Fehlt noch was? Ach ja, die Erzeugung der CSV-Datei mit Hilfe der Funktion erzeuge_csv(), damit halte ich mich jetzt nicht lange auf, die ist einigermassen selbsterklärend:
function erzeuge_csv($liste){
global $wpdb;
echo "Ich erzeuge jetzt ein csv: ";
//***************
// Verzeichis des aktuellen Plugins ermitteln
$dir = plugin_dir_path( __FILE__ );
$aktVerzeichnis = $dir;
//Dateiname fest verdrahtet
$fileName = $aktVerzeichnis.'stichwortliste.csv';
echo $fileName."</br>";
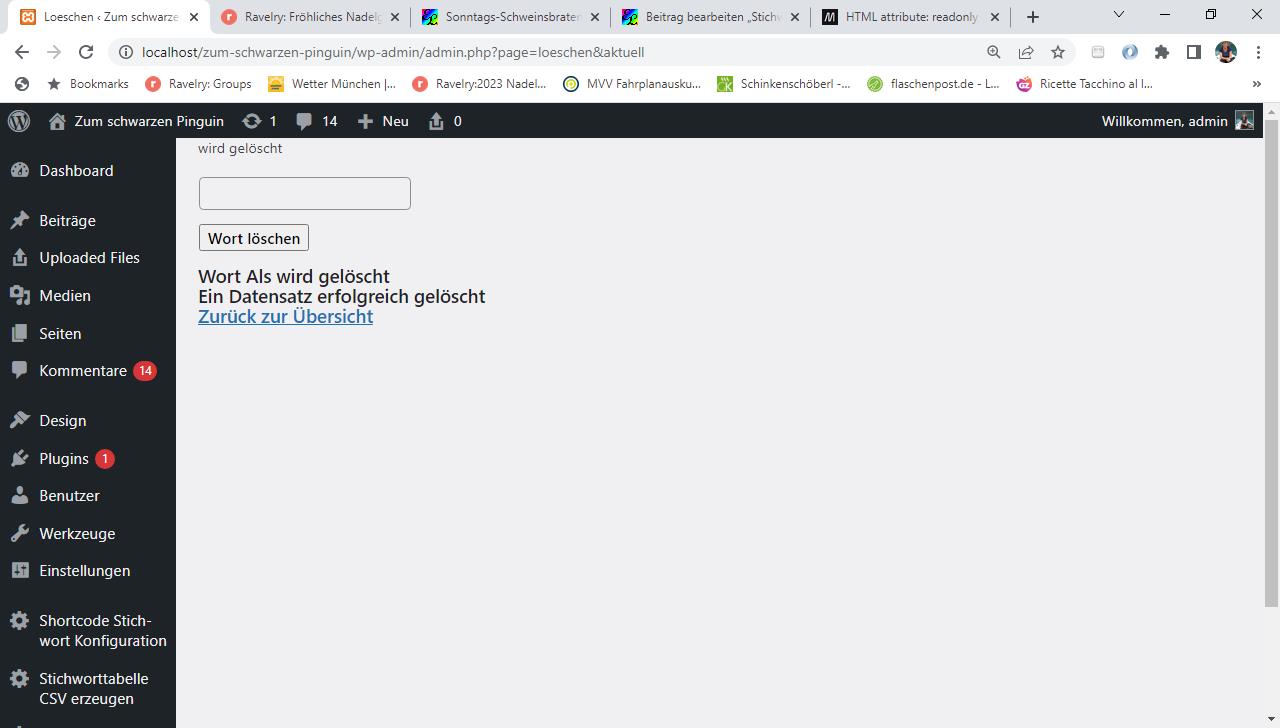
if(file_exists($fileName)){
echo "Die alte Datei wird überschrieben</br>";
}
//Gnadenlos überschreiben, der Parameter 'w' ersetzt den alten Dateiinhalt
$csvFile = fopen($fileName,'w');
$head = ["Wort"];
fputcsv($csvFile,$head);
// Variable mit den Listeneinträgen befüllen
foreach ($liste as $einwort){
$data = [
["$einwort"],
];
//Durch alle data-Einträge durchsteppen und in Datei schreiben
foreach($data as $row){
fputcsv($csvFile,$row);
}
}
fclose($csvFile);
//Debug-Ausgabe aller Stichworte
$anzahl = sizeof($liste);
echo "<h2>Testausgabe: ".$anzahl." Stichwörter erzeugt</h2>";
foreach ($liste as $stichwort){
echo $stichwort."</br>";
}
}// Ende function erzeuge csv
//*****************************************
Falls die Datei nicht existiert, wird sie neu angelegt. Falls sie schon existiert, wird der Inhalt überschrieben. So das wars. Jetzt einen Kaffee und sacken lassen. Und dann Hurra auf zu neuen Ufern, jetzt kommt der Teil mit dem Shortcode. Aber dazu gibts einen neuen Beitrag.